library(sjlabelled)
mydata<-read_spss("stfood2019.sav")Converting atomic to factors. Please wait...假设你透过问卷星系统做了一个网络问卷,得到1058位成功受访者(样本,1058人),想要推论的目标对象是某高校某年度新闻传播学院的本科生(总体,3050人),你把成功样本的性别、年级以及学系三个变量的频数分布与总体应有的比例做一对照,做成一个对照表(如下)。请问:这个调查问卷的成功样本,在性别、年级以及学系三个变量上,能不能代表总体?具有样本代表性吗?如果样本不具代表性,又该如何解决呢?
| 检验变量 | 变量值及标签 | 样本% | 总体% |
|---|---|---|---|
| sex[性别] | 1:男 | 39.2% | 24.2% |
| 2:女 | 60.8% | 75.8% | |
| class[年级] | 1:大一大二 | 51.2% | 49.4% |
| 2:大三大四 | 48.8% | 50.6% | |
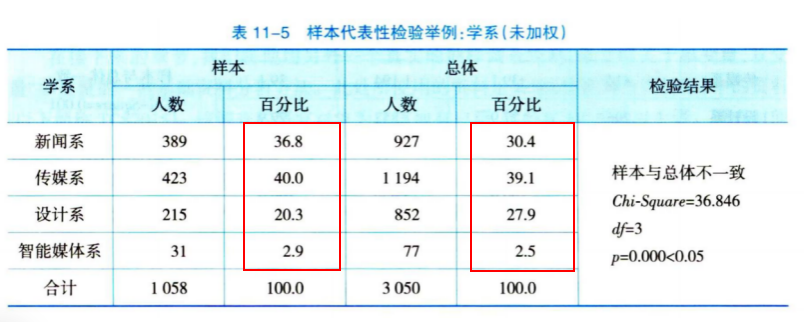
| dep[学系] | 1:新闻系 | 36.8% | 30.4% |
| 2:传媒系 | 40.0% | 39.1% | |
| 3:设计系 | 20.3% | 27.9% | |
| 4:智能媒体系 | 2.9% | 2.5% | |
| Total | 100.0% (n=1058) | 100.0% (N=3050) |
SPSS的菜单操作如下:
Analyze -> Nonparametric Tests -> Legacy Dialogs -> Chi-square
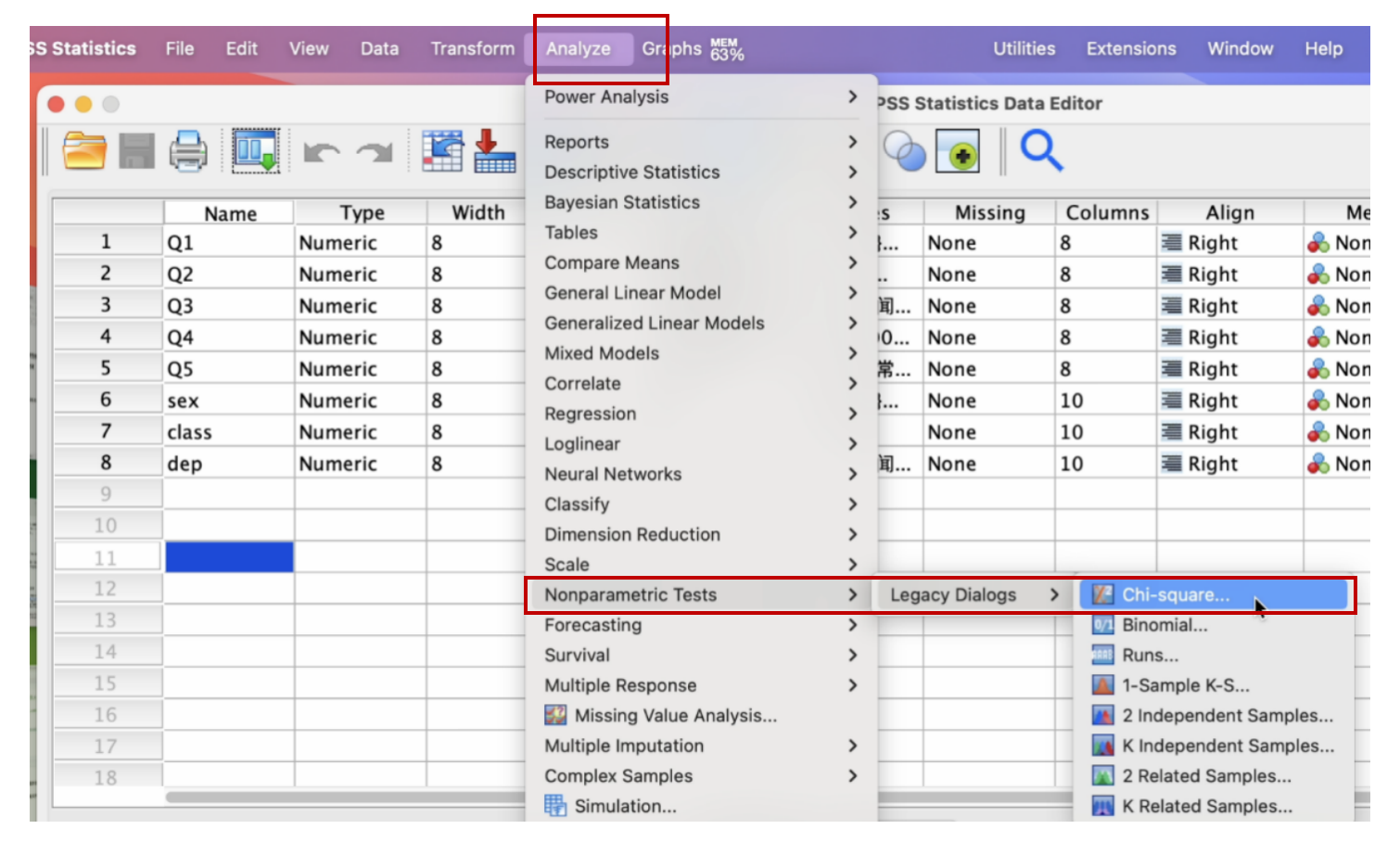
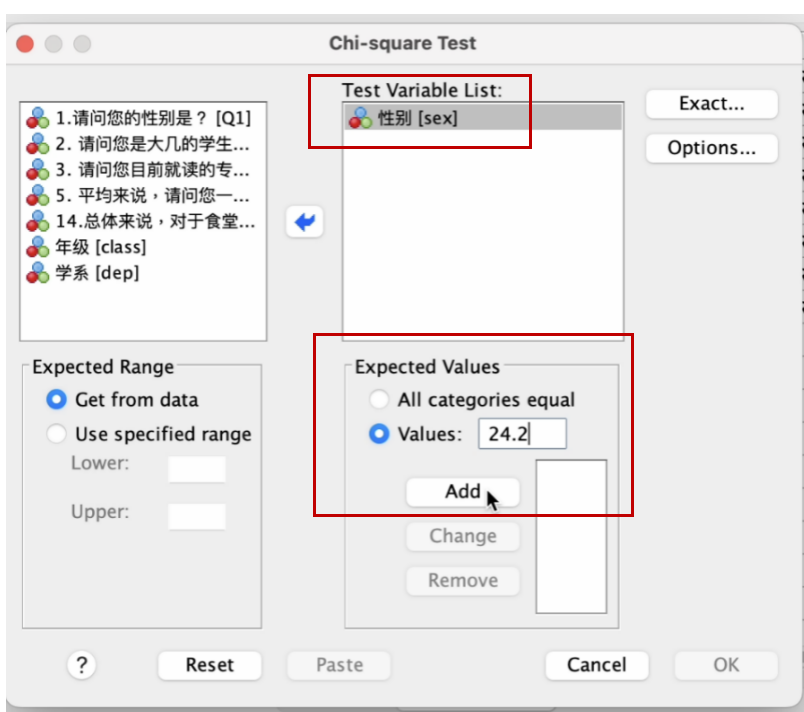
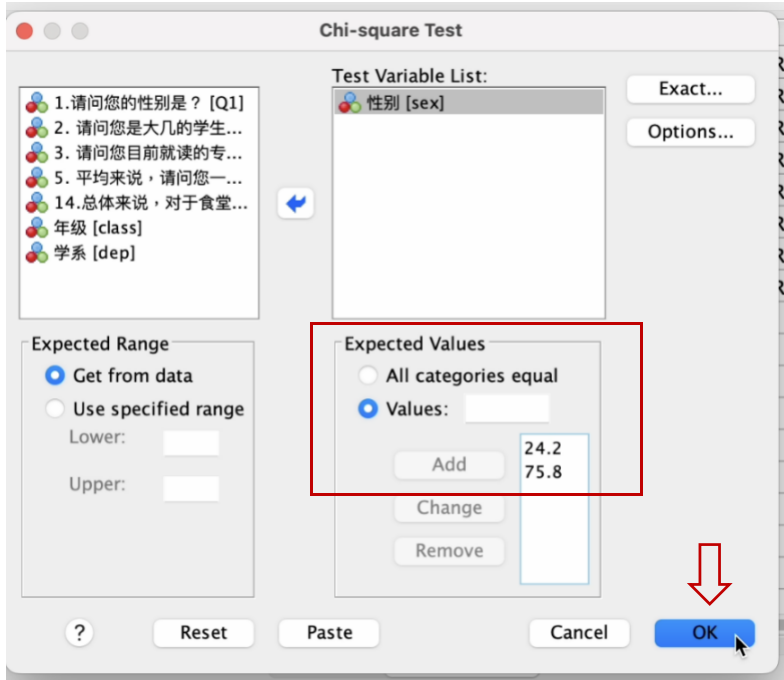
进入 Chi-square Test 窗口,将左边方框内的 性别[sex] 变量,移到右边 Test Variable List 方框内。然后点选 Expected Values 下的 Values 前的圆点,分别输入:
24.2(男性在总体中应有的比例),再点击一下 Add 方框;
75.8(女性在总体中应有的比例),再点击一下 Add 方框;
然后点击 OK 方框,如以下两个图所示。
sex (性别)变量的样本代表性检验结果,会呈现在 输出(output) 窗口,如下图:
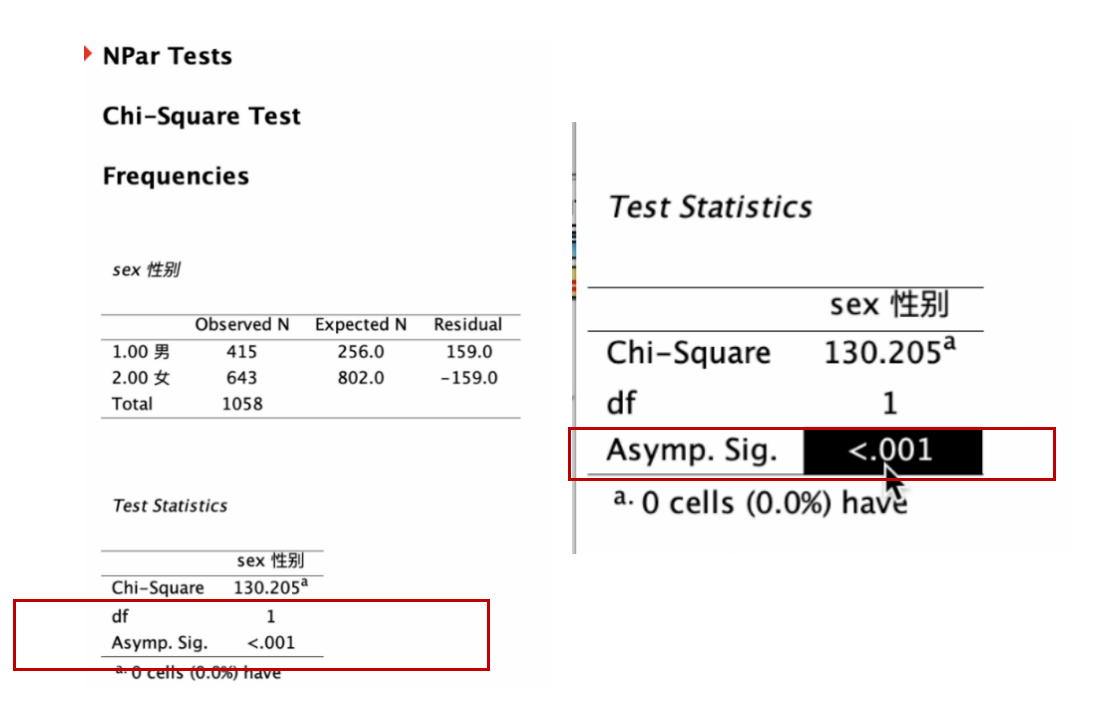
我们只需要看报表中的 Asymp.Sig. (显著性),又可称为 P, Probabilities之意) 所对应的数值。 如果这个数值P ≦ 0.05, 代表样本的变量分布与总体不一致,无法代表总体。 如果这个数值P > 0.05,代表 样本的变量分布与总体一致,可以代表总体。
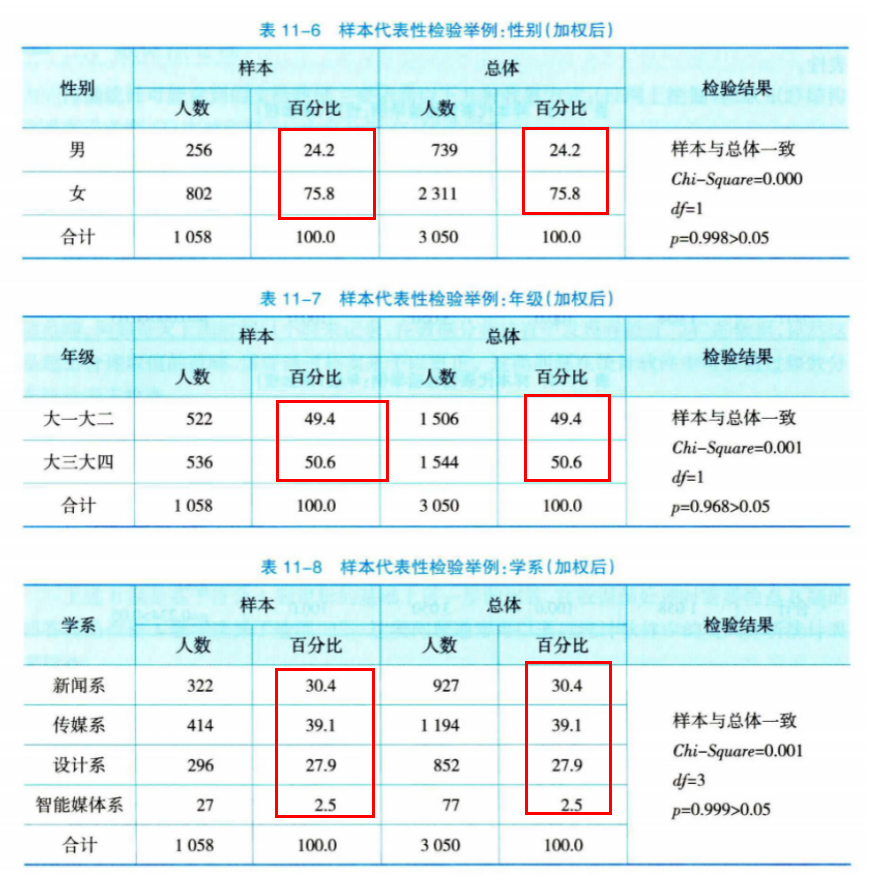
此例,样本 sex(性别) 变量的Chi-Square=130.205, 其所对应的 Asymp.Sig.(显著性, P)< 0.001, 即 P < 0.05。 所以样本的 性别 结构与总体不一致,无法代表总体(参见课本Ch11, 表11-3,如下)。
依循上述同样的操作方式,
Analyze -> Nonparametric Tests -> Legacy Dialogs -> Chi-square
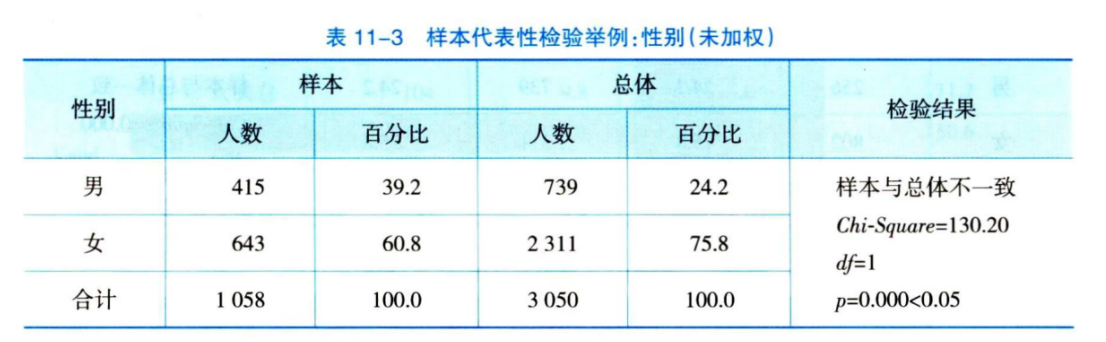
进入 Chi-square Test 窗口,将左边方框内的 年级[class] 变量,移到右边 Test Variable List 方框内。然后点选 Expected Values 下的Values前的圆点,分别输入: 49.4(大一大二在总体应有的比例),再点击一下Add; 50.6(大三大四在总体应有的比例),再点击一下Add; 最后点击OK 方框,如下图。
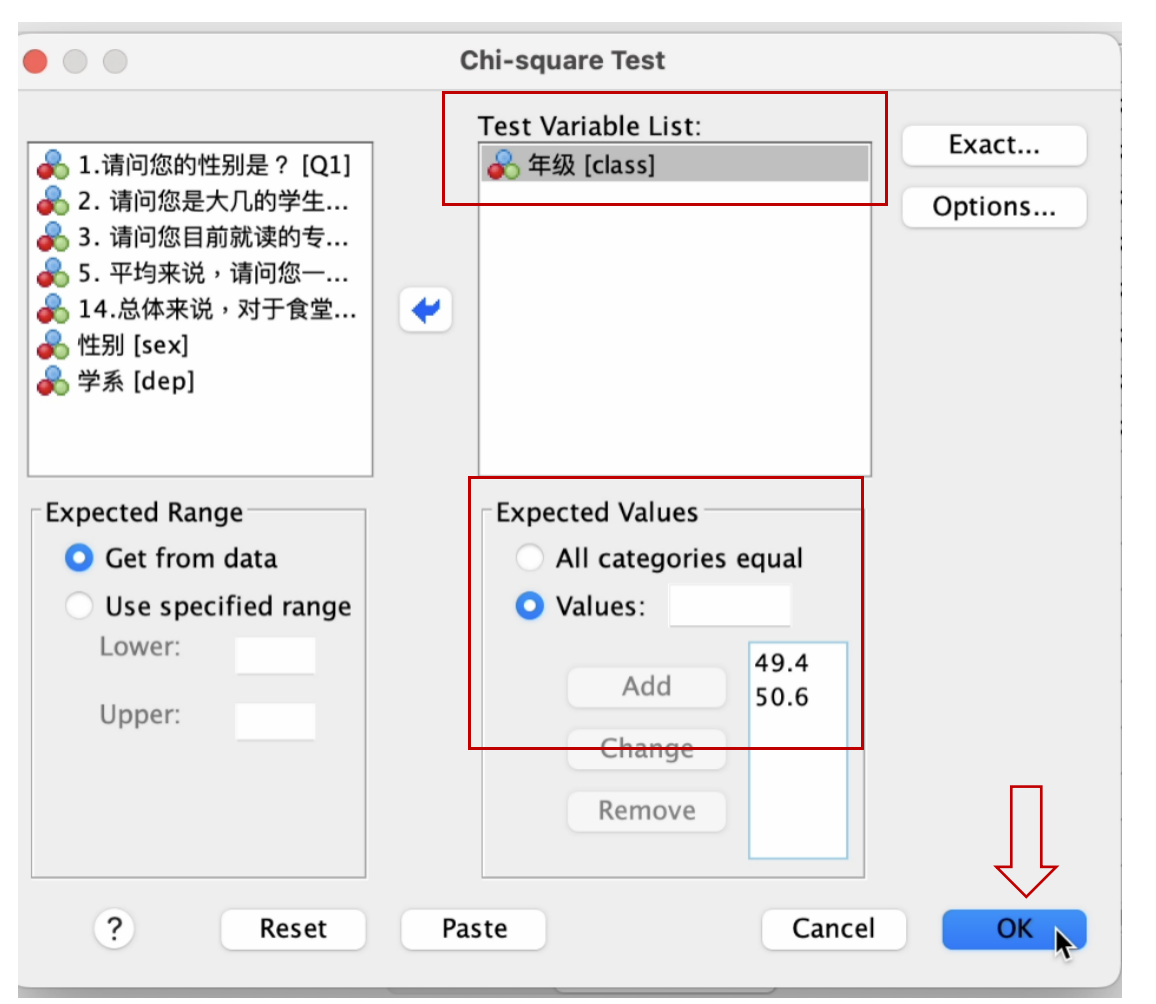
class (年级)变量的样本代表性检验结果,会呈现在 输出(output) 窗口,如下图。
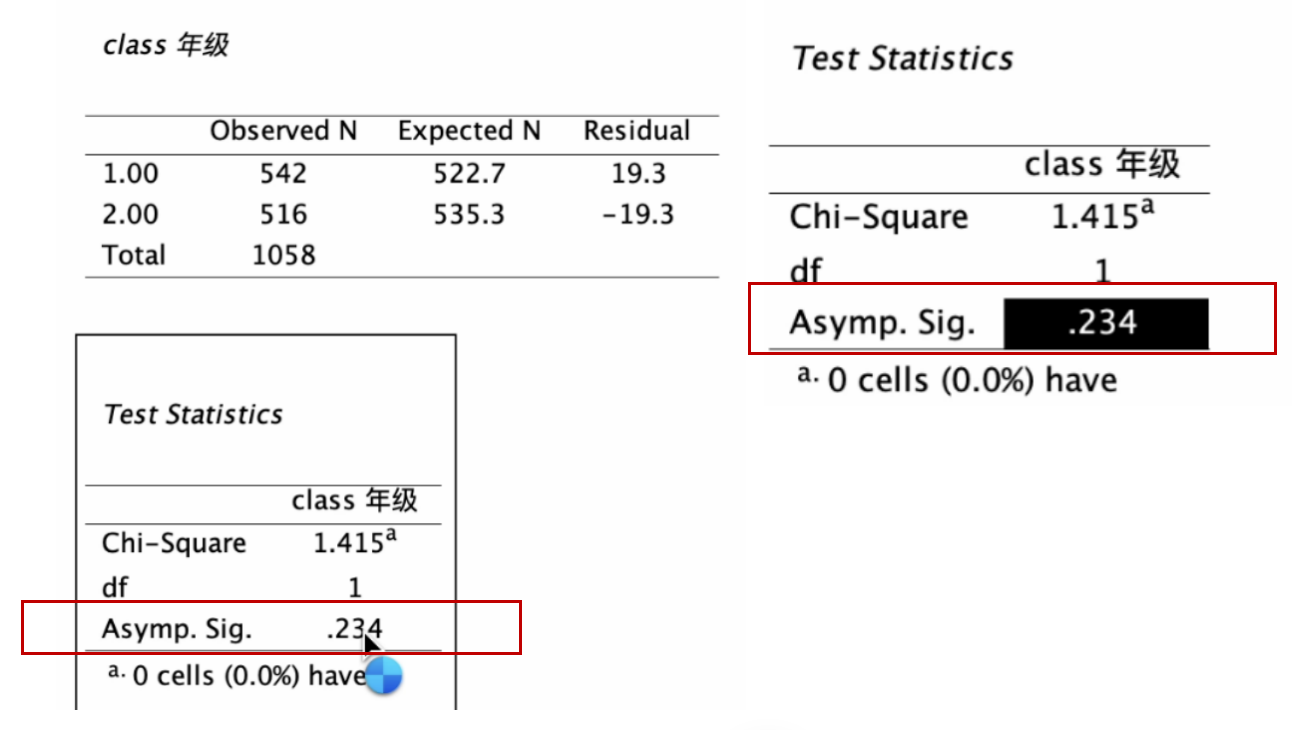
此例,样本 class (年级) 变量的Chi-Square=1.415, 其所对应的 Asymp.Sig.(显著性, P)= 0.234 > 0.05, 貌似 样本的 年级 结构与总体一致。
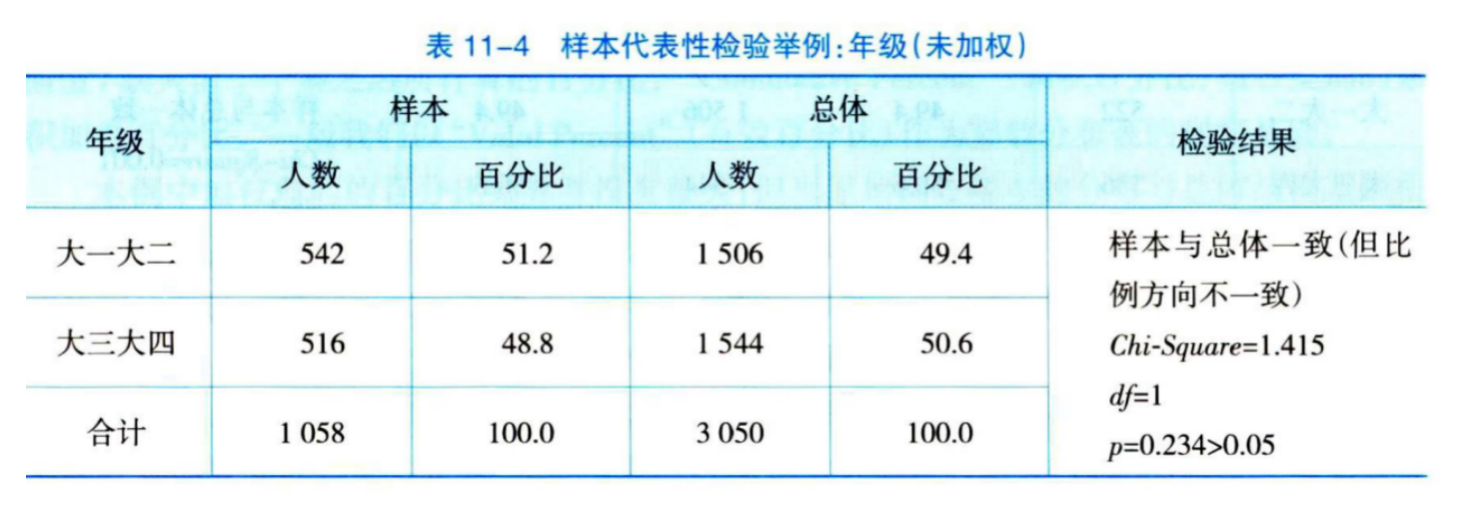
然而,如果我们细看 class(年级) 变量的分布比例,可以发现, 总体中 大一大二 所占的比例(49.4%)是小于 大三大四(50.6%)。但样本中,大一大二所占的比例(51.2%)却是大于 大三大四(48.8%)。
所以综合来看,我们的结论是:样本的 class (年级) 结构与总体不一致,无法代表总体(参见课本Ch11 表11-4,如下)。
依循上述同样的操作方式,
Analyze -> Nonparametric Tests -> Legacy Dialogs -> Chi-square
进入 Chi-square Test 窗口,将左边方框内的 学系[dep] 变量,移到右边 Test Variable List 方框内。然后点选 Expected Values 下的 Values 前的圆点,分别输入: 30.4(新闻系在总体中应有的比例), 再点击 Add 方框; 39.1(传媒系在总体中应有的比例), 再点击 Add 方框; 27.9(设计系在总体中应有的比例), 再点击 Add 方框; 2.5 (智能媒体系在总体应有的比例),再点击 Add 方框; 最后点击 OK 方框,如下图。
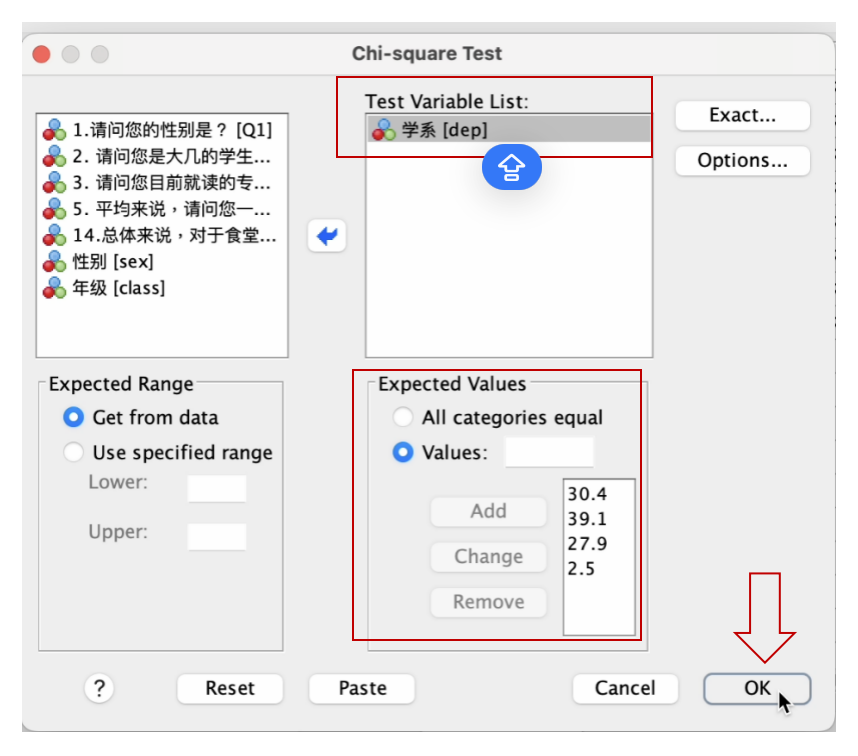
dep (学系)变量的样本代表性检验结果,会呈现在 输出(output) 窗口,如下图。
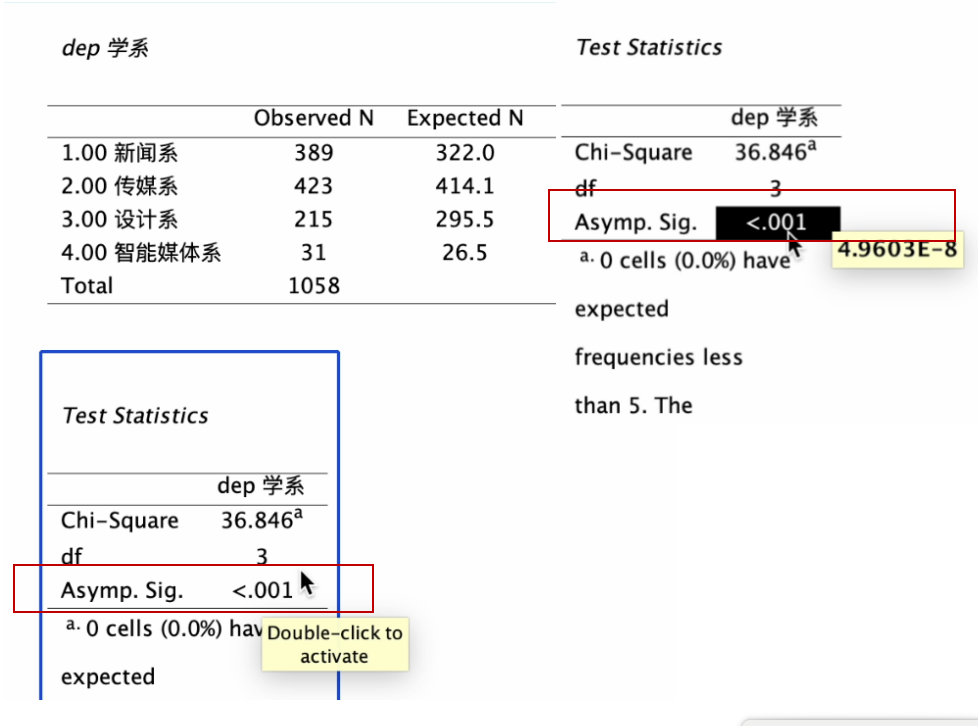
此例,样本 dep(学系) 变量的Chi-Square=36.846, 其所对应的 Asymp.Sig.(显著性, P)< 0.001, 即 P < 0.05。 所以样本的 学系变量结构与总体不一致,无法代表总体(参见课本Ch11 表11-5,如下)。
当样本无法代表总体时,研究者通常会进一步使用 加权 (Weighting) 的方法,产生一个新的加权变量。这个加权变量,基本上是分析变量的 总体比例╱样本比例。透过加权,可以将样本中过少的样本数予以扩大,将过多的样本数予以缩小,以使加权后的样本能够代表总体。常用的加权方法为 多变量反覆加权 (Raking)。例如,以 性别 × 年级 × 学系这三个变量,反覆加权,直到样本的 性别、年级 与 学系 分布结构,都可以代表总体。
SPSS多变量反覆加权的步骤如下:
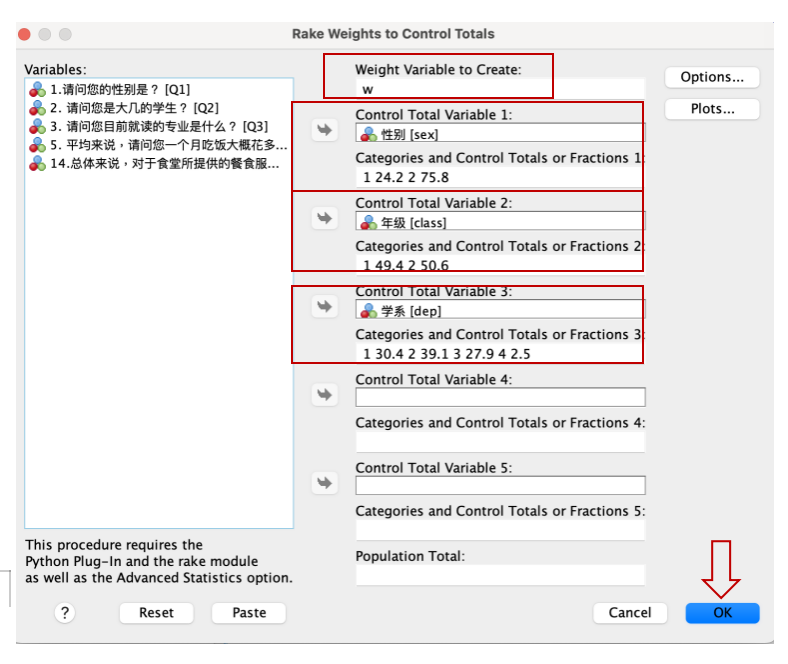
Data -> Rake Weights
在 Rake Weights to Control Totals 窗口,Weight Variable to Create方框,先输入我们想产生的加权变量的变量名称(本例,设置为 w)。
之后,将左边方框内的 性别[sex] 变量,移到右边 Control Total Variable 1内,并在 Categories and Control Totals or Fractions 1 一一输入加权变量 性别[sex] 的每个变量值及总体比例。
本例:性别[sex] [1 24.2 2 75.8],代表 :性别[sex] 变量中的
变量值 1(男性),在总体中应占24.2%;
变量值 2(女性),在总体中应占75.8%。
接下来,将左边方框内的 年级[class] 变量,移到右边 Control Total Variable 2内,并在 Categories and Control Totals or Fractions 2 一一输入加权变量 年级[class] 的每个变量值及总体比例。
本例:年级[class] [1 49.4 2 50.6],代表 年级[class] 变量中的
变量值 1(大一大二),在总体中应占49.4%;
变量值 2(大三大四),在总体中应占50.6%。
继续,将左边方框内的 学系[dep] 变量,移到右边 Control Total Variable 3 内,并在 Categories and Control Totals or Fractions 3 一一输入加权变量 学系[dep] 的每个变量值及总体比例。
本例:学系[dep] [1 30.4 2 39.1 3 27.9 4 2.5 ],代表 学系[dep] 变量中的
变量值 1(新闻系),在总体中应占30.4%;
变量值 2(传媒系),应在总体中占39.1%;
变量值 3(设计系),应在总体中占27.9%;
变量值 4(智能媒体系),应在总体中占2.5%。
全部输入完后,点击 OK ,SPSS就会开始运行。如下图。
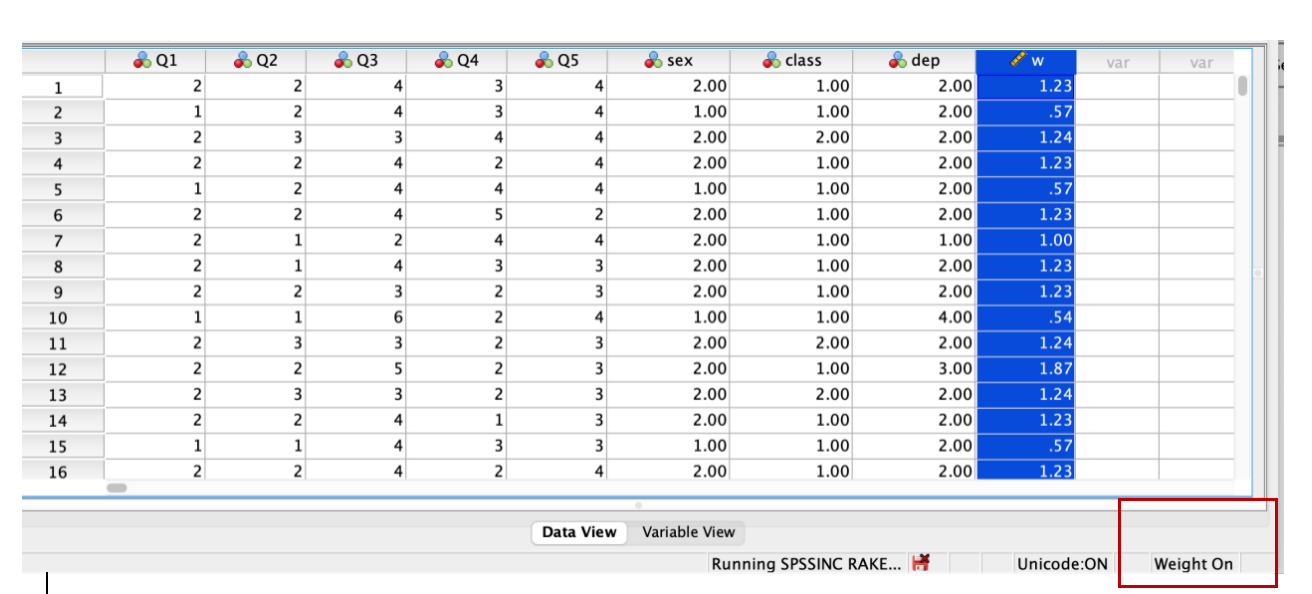
运行结束后,SPSS就会在数据档产生一个新的变量 w ,这就是经过性别 × 年级 × 学系这三个变量反覆加权后,所产生的加权变量。当数据档处于加权状态时,数据档的右下角会呈现 weight on字样,如下图。
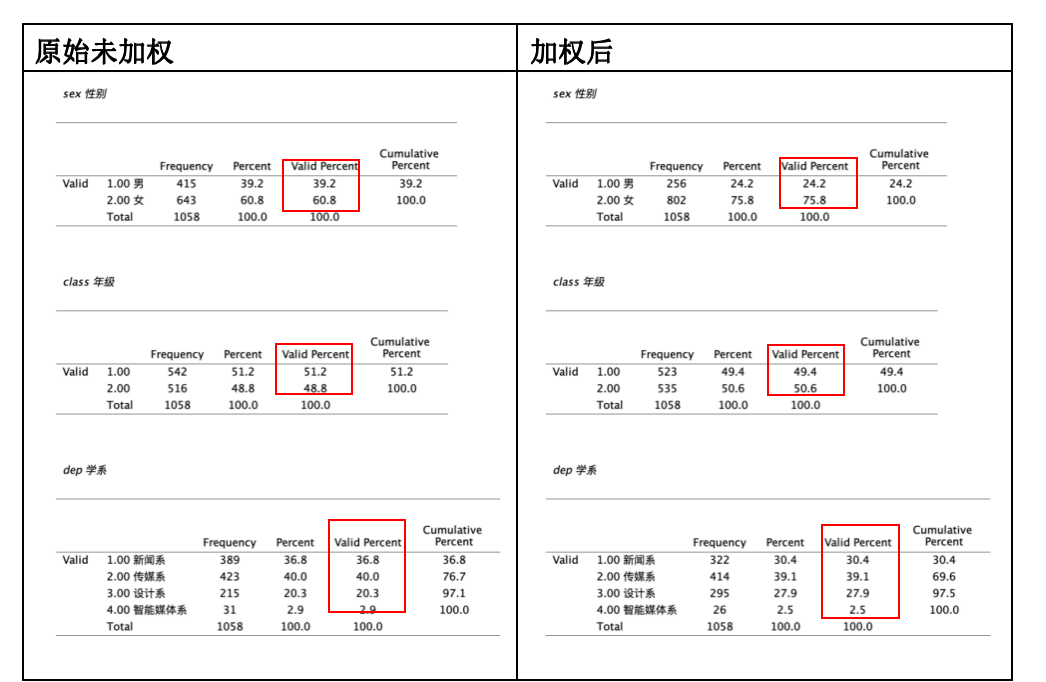
加权后与原始未加权的频数百分比经加权后,样本的性别、年级与学系分布,具有代表性,可以代表总体,如下图。
可以把SPSS跑出来的结果,手工做个整理,会更清楚两者的差异。(参看课本Ch11 表11-6,如下)。
此外,在加权状态下,我们也可以看一下Q5这题的频数分布。
仿照之前学习过的频数分布,我们得到Q5这题的加权后频数分布操作程序如下:
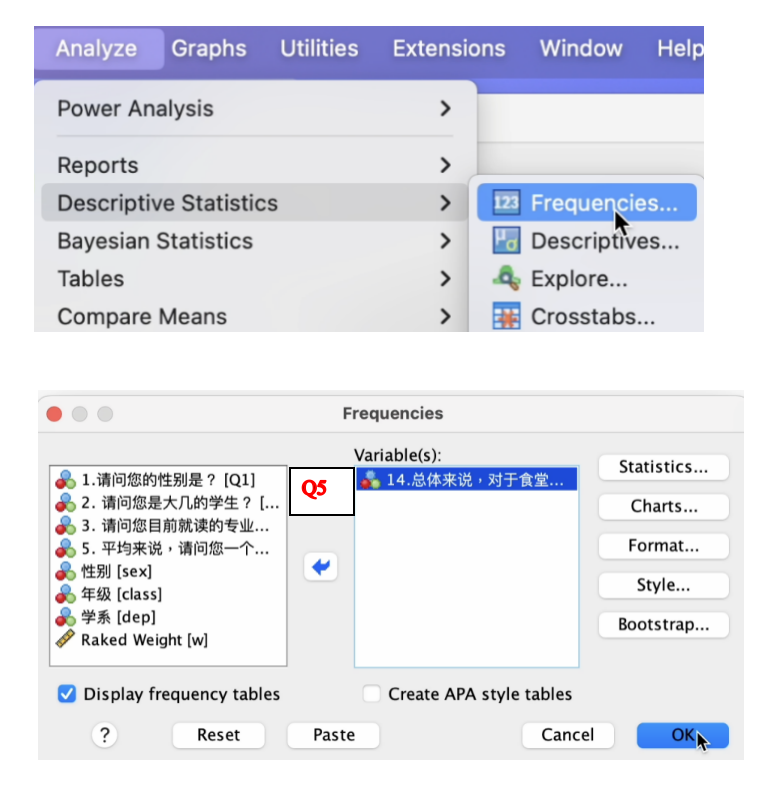
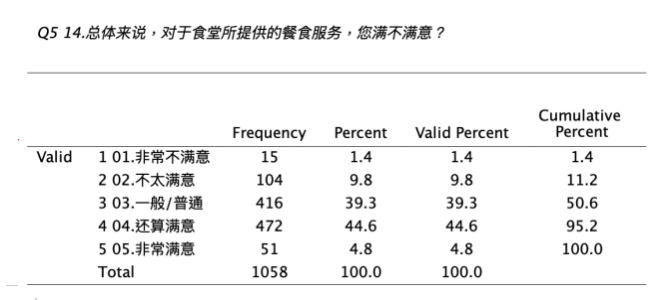
加权后频数分布的SPSS报表结果如下:
那,我们如何得到原始未加权的频数百分比呢?
首先,我们先将加权变量从数据档中卸除,
SPSS的操作如下: Data -> Weight Cases
在 Weight Cases 窗口, 点选 Do not weight cases 前面的圆圈选项。 然后点击OK 。如下图。
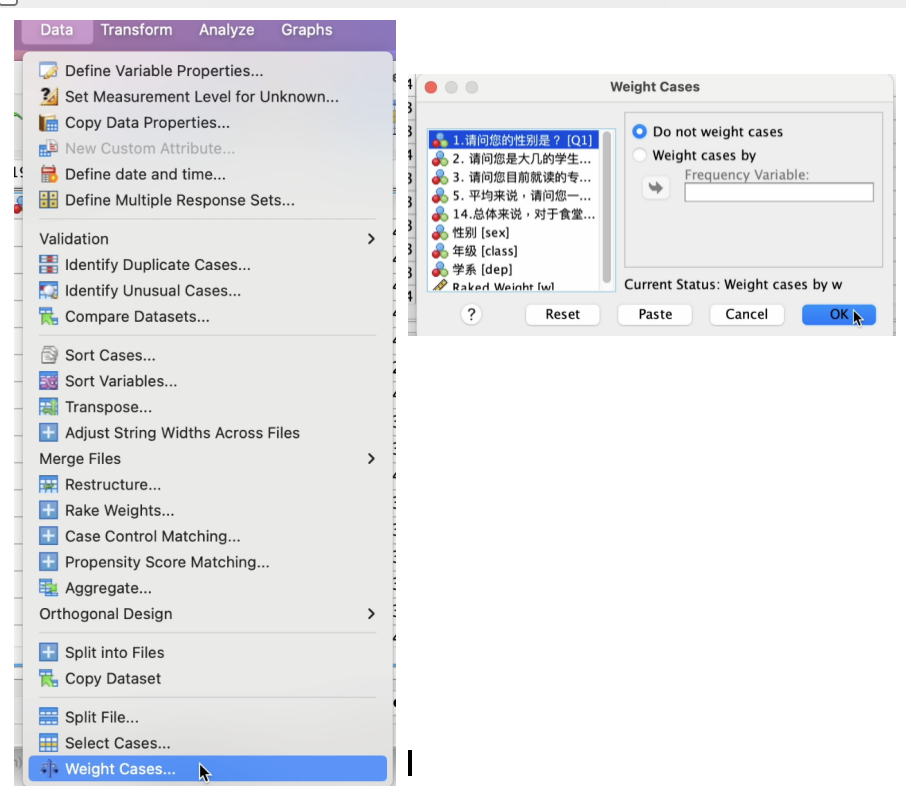
卸除加权变量之后,重复学习过的频数分布操作方法,如下图。
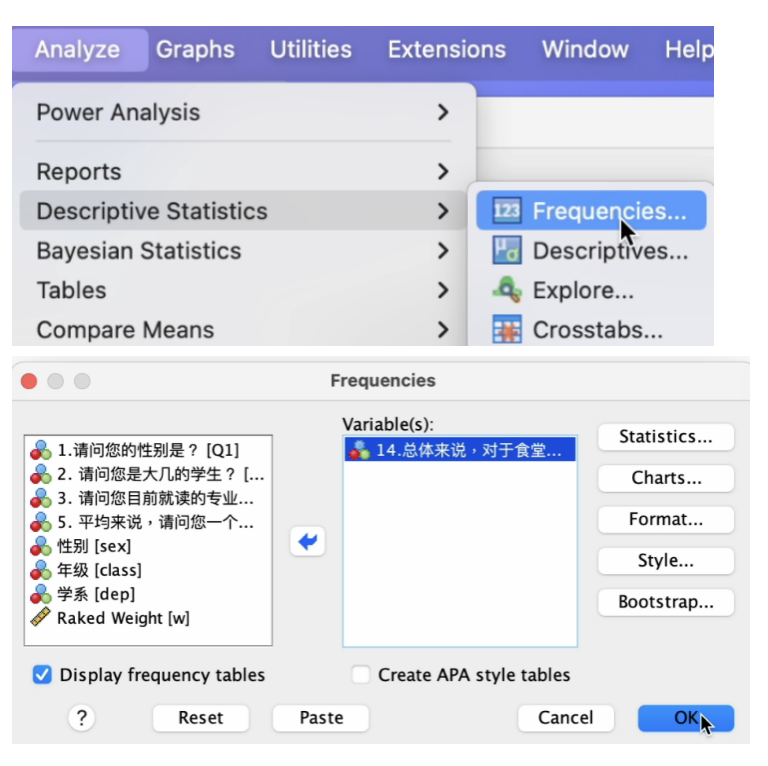
就可得到Q5变量原始未加权的频数分布。如下图。
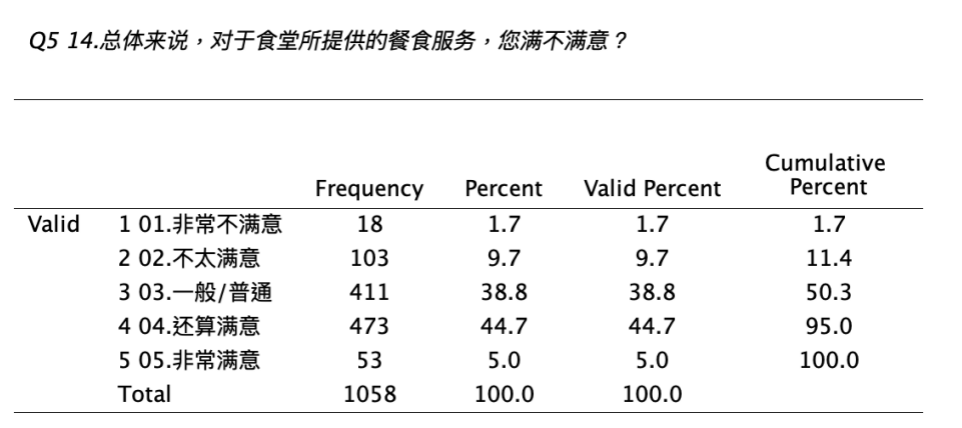
将Q5两个频数分布表放在一起比较,可以更清楚看到两者的差异。
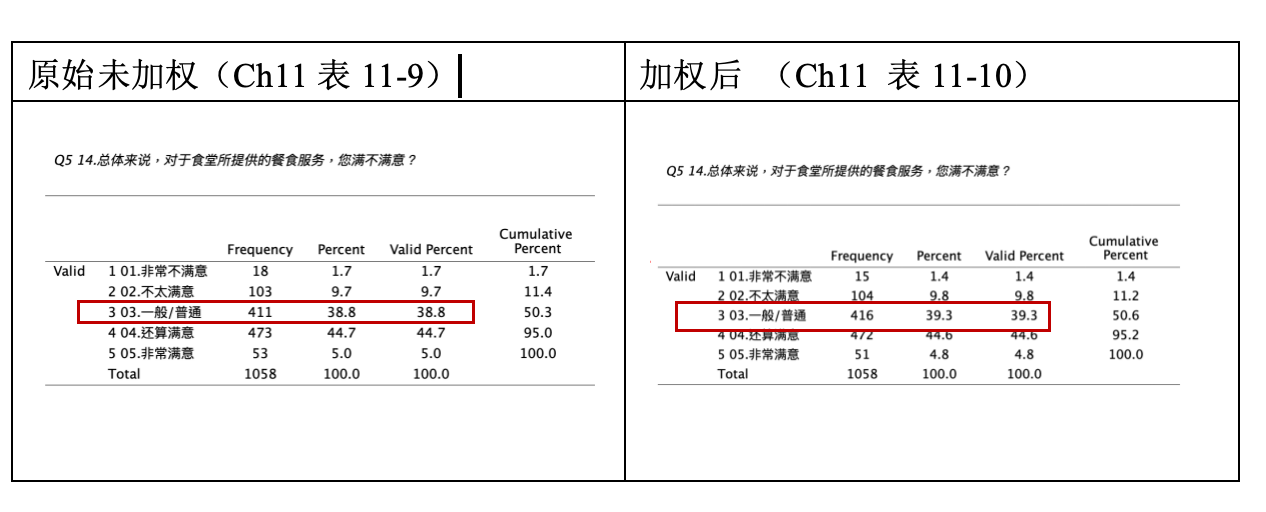
我们发现,原始未加权与加权后,最大差异发生在 “一般/普通” 的选项。原始未加权的 “一般/普通” 为38.8%,加权后的 “一般/普通”为39.3%,那要采用哪一个结果呢?我们应采用加权后的频数分布百分比,因为加权后的频数百分比是具有样本代表性的频数百分比。
SPSS操作如下:
Data -> Weight Cases
在 Weight Cases 窗口,将加权变量(本例为 w) (Raked Weight)从左边方框移到: Weight cases by -> Frequency Variable 的方框内, 然后点击 OK。如下图。
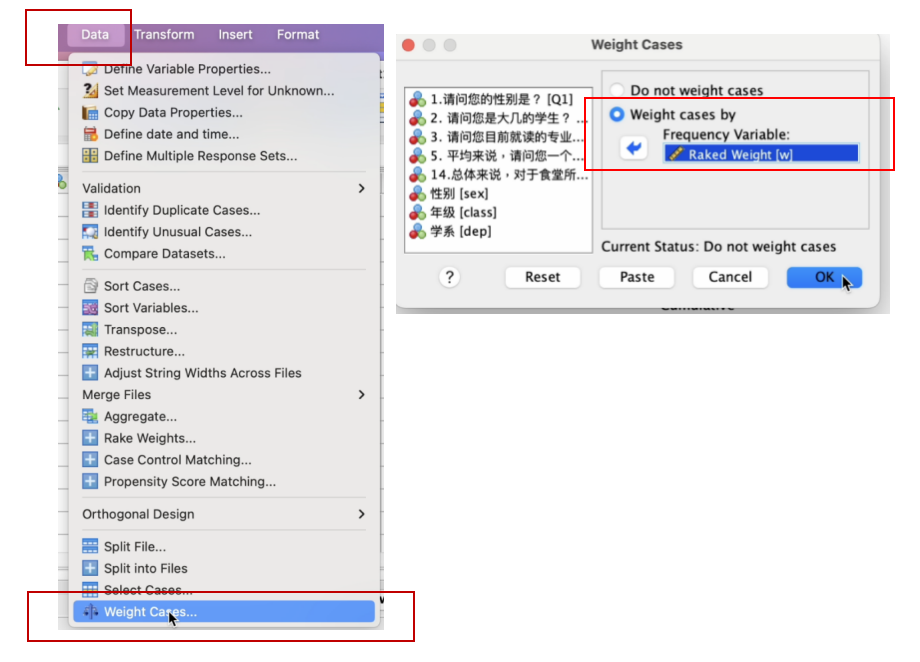
当加权变量被挂上数据档之后, SPSS数据档窗口的右下角,就会呈现 Weight on 的字样,此时,研究者如果要做数据分析,就会呈现基于加权变量所呈现的分析结果。
阅读本讲讲义,另请参阅:
王晓华、郭良文(2022)[1] 第十一章 (量化资料分析-数字会说话), 页196-199。
library(sjlabelled)
mydata<-read_spss("stfood2019.sav")Converting atomic to factors. Please wait...if(!require("sjstats")) install.packages("sjstats")载入需要的程序包:sjstatslibrary(sjstats)
#输入检验变量应有的总体比例
chi_squared_test(mydata, "sex",
probabilities = c(.242,.758))# Chi-squared test for given probabilities
Data: sex against probabilities 24% and 76% (n = 1058)
χ² = 130.205, פ = 0.198 (small effect), df = 1, p < .001chi_squared_test(mydata, "class",
probabilities = c(.494,.506))# Chi-squared test for given probabilities
Data: class against probabilities 49% and 51% (n = 1058)
χ² = 1.415, פ = 0.036 (tiny effect), df = 1, p = 0.234chi_squared_test(mydata, "dep",
probabilities = c(.304, .391, .279, .026))# Chi-squared test for given probabilities
Data: dep against probabilities 30%, 39%, 28% and 3% (n = 1058)
χ² = 36.544, פ = 0.030 (tiny effect), df = 3, p < .001检验结果显示,原始数据的 “性别”(sex)、“年级”(class) 与 “学系”(dep)分布,未通过样本代表性检验(p < 0.05)。
library(sjstats)
chi_squared_test(mydata, "sex",
probabilities = c(.242,.758),
weights = "w")# Chi-squared test for given probabilities (weighted)
Data: sex against probabilities 24% and 76% (n = 1058)
χ² = 0.000, פ = 0.000 (tiny effect), df = 1, p = 0.998chi_squared_test(mydata,
"class", probabilities = c(.494,.506),
weights = "w")# Chi-squared test for given probabilities (weighted)
Data: class against probabilities 49% and 51% (n = 1058)
χ² = 0.000, פ = 0.001 (tiny effect), df = 1, p = 0.983chi_squared_test(mydata, "dep",
probabilities = c(.304, .391, .279, .026),
weights = "w")# Chi-squared test for given probabilities (weighted)
Data: dep against probabilities 30%, 39%, 28% and 3% (n = 1057)
χ² = 0.083, פ = 0.001 (tiny effect), df = 3, p = 0.994检验结果显示,原始数据的 “性别”(sex)、“年级”(class) 与”学系”(dep)分布,皆通过样本代表性检验(p > 0.05)
library(sjmisc)
frq(mydata$sex, out = "v", weights = mydata$w)| val | label | frq | raw.prc | valid.prc | cum.prc | |
|---|---|---|---|---|---|---|
| 1 | 男 | 256 | 24.20 | 24.20 | 24.20 | |
| 2 | 女 | 802 | 75.80 | 75.80 | 100.00 | |
| NA | NA | 0 | 0.00 | NA | NA | |
| total N=1058 · valid N=1058 · x̄=1.76 · σ=0.43 | ||||||
frq(mydata$class, out = "v", weights = mydata$w)| val | label | frq | raw.prc | valid.prc | cum.prc | |
|---|---|---|---|---|---|---|
| 1 | 大一大二 | 523 | 49.43 | 49.43 | 49.43 | |
| 2 | 大三大四 | 535 | 50.57 | 50.57 | 100.00 | |
| NA | NA | 0 | 0.00 | NA | NA | |
| total N=1058 · valid N=1058 · x̄=1.51 · σ=0.50 | ||||||
frq(mydata$dep, out = "v", weights = mydata$w)| val | label | frq | raw.prc | valid.prc | cum.prc | |
|---|---|---|---|---|---|---|
| 1 | 新闻系 | 322 | 30.46 | 30.46 | 30.46 | |
| 2 | 传媒系 | 414 | 39.17 | 39.17 | 69.63 | |
| 3 | 设计系 | 295 | 27.91 | 27.91 | 97.54 | |
| 4 | 智能媒体系 | 26 | 2.46 | 2.46 | 100.00 | |
| NA | NA | 0 | 0.00 | NA | NA | |
| total N=1057 · valid N=1057 · x̄=2.03 · σ=0.83 | ||||||
#原始未加权
frq(mydata$Q5, out = "v")| val | label | frq | raw.prc | valid.prc | cum.prc | |
|---|---|---|---|---|---|---|
| 1 | 01.非常不满意 | 18 | 1.70 | 1.70 | 1.70 | |
| 2 | 02.不太满意 | 103 | 9.74 | 9.74 | 11.44 | |
| 3 | 03.一般/普通 | 411 | 38.85 | 38.85 | 50.28 | |
| 4 | 04.还算满意 | 473 | 44.71 | 44.71 | 94.99 | |
| 5 | 05.非常满意 | 53 | 5.01 | 5.01 | 100.00 | |
| NA | NA | 0 | 0.00 | NA | NA | |
| total N=1058 · valid N=1058 · x̄=3.42 · σ=0.80 | ||||||
#加权后
frq(mydata$Q5, out = "v", weights = mydata$w)| val | label | frq | raw.prc | valid.prc | cum.prc | |
|---|---|---|---|---|---|---|
| 1 | 01.非常不满意 | 15 | 1.42 | 1.42 | 1.42 | |
| 2 | 02.不太满意 | 104 | 9.83 | 9.83 | 11.25 | |
| 3 | 03.一般/普通 | 416 | 39.32 | 39.32 | 50.57 | |
| 4 | 04.还算满意 | 472 | 44.61 | 44.61 | 95.18 | |
| 5 | 05.非常满意 | 51 | 4.82 | 4.82 | 100.00 | |
| NA | NA | 0 | 0.00 | NA | NA | |
| total N=1058 · valid N=1058 · x̄=3.42 · σ=0.79 | ||||||