1 相关分析
1.1 基本概念图解
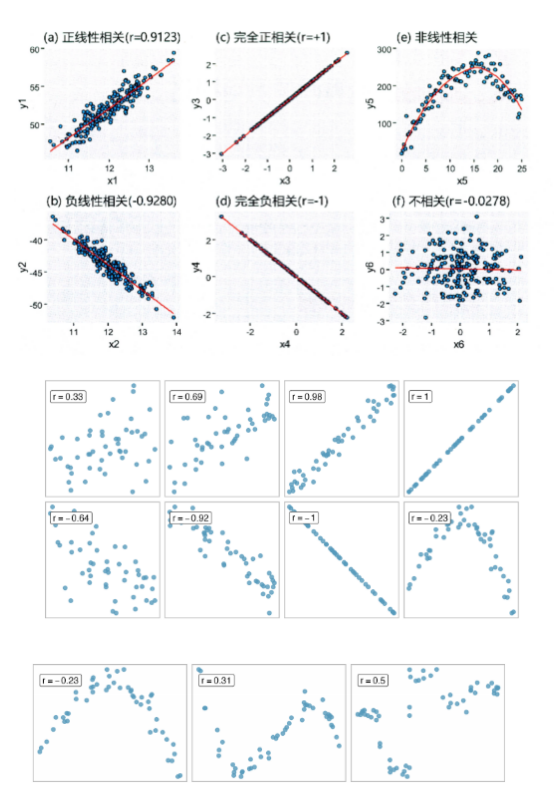
1.2 使用相关分析的目的
当我们想要了解两个(或多个)连续变量之间的关系模式(正相关、负相关、非线性相关、或不相关)及相关强度时,我们经常会使用 相关分析。
1.3 相关分析SPSS操作与报表解读
1.3.1 数据准备 (TCS2015sc_Ch11.sav)
首先,启动SPSS软件,进入主界面。导入包含因变量和自变量的数据档案(本例:TCS2015sc_Ch11.sav)。
1.3.2 执行SPSS相关分析
在SPSS中,选择 Analyze -> Correlate -> Bivariate。 如 Figure 2 所示:
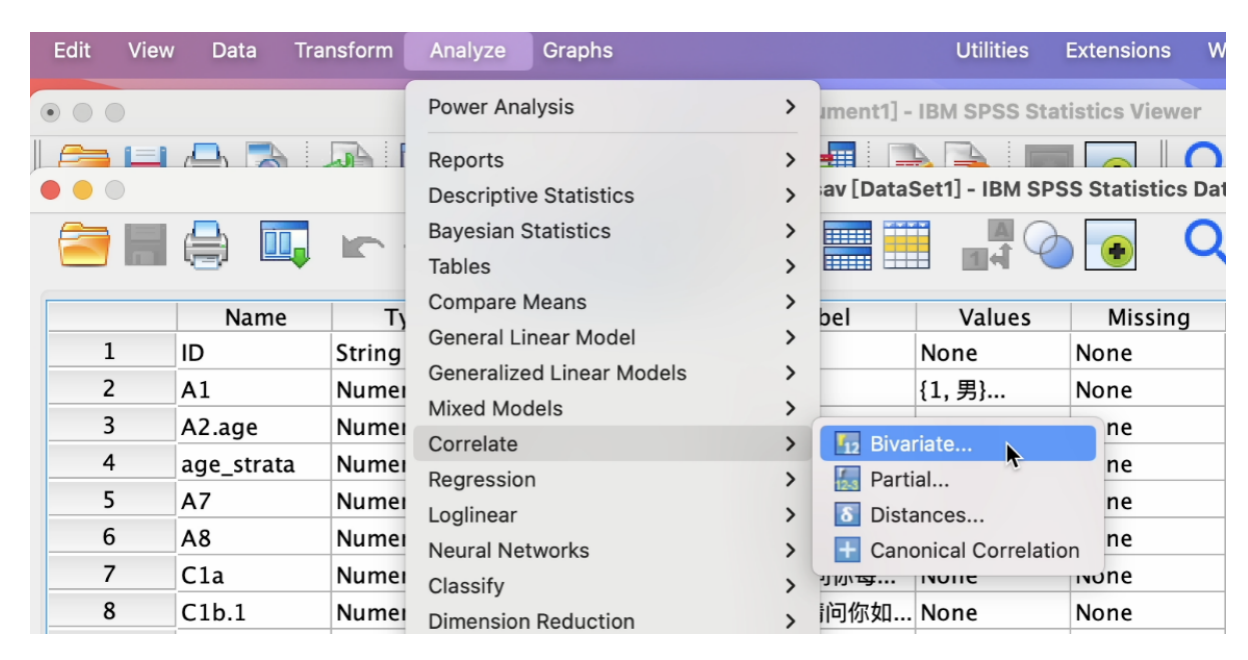
在弹出的 Bivariate Correlaitons窗口, 将两个数字变量:H4.5(请你就下列媒体新闻报道的整体表现给一个分数-网络)与 smuse_hour_day (每天使用社交媒体的时间-小时数),自左边的变量方框,移到右边的 Variables 方框内。继续点选 Options 按钮。 如 Figure 3 所示:
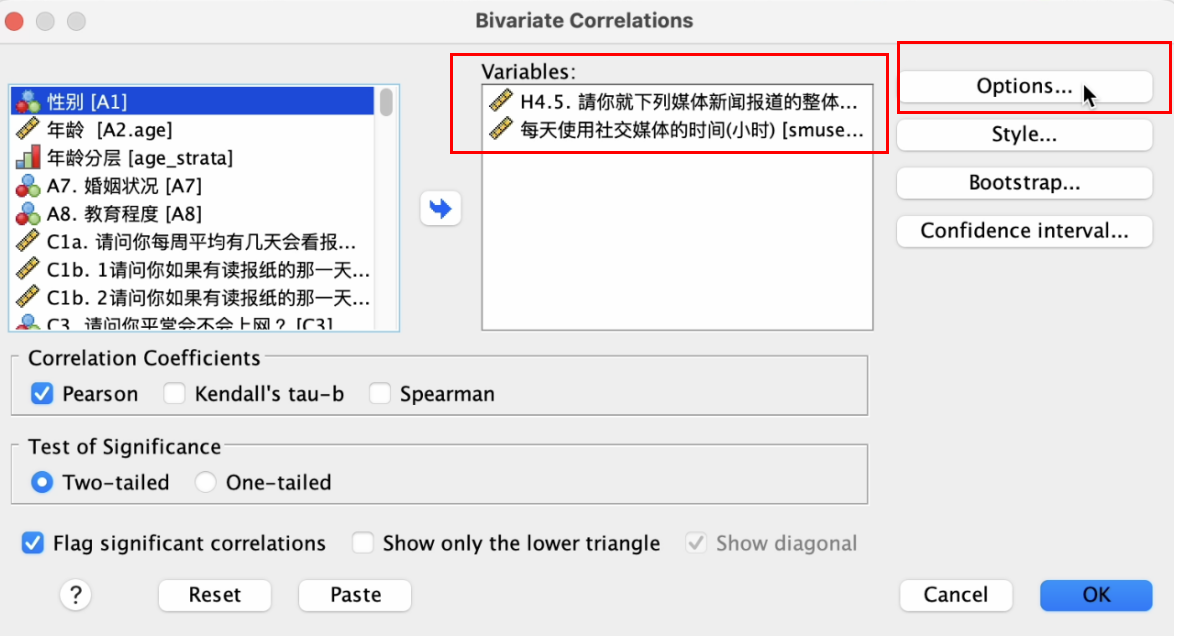
在弹出的 Bivariate Correlaitons: Options 窗口中, 点选 Means and standard deviations, 然后点选 Continue 按钮。 如 Figure 4 所示:
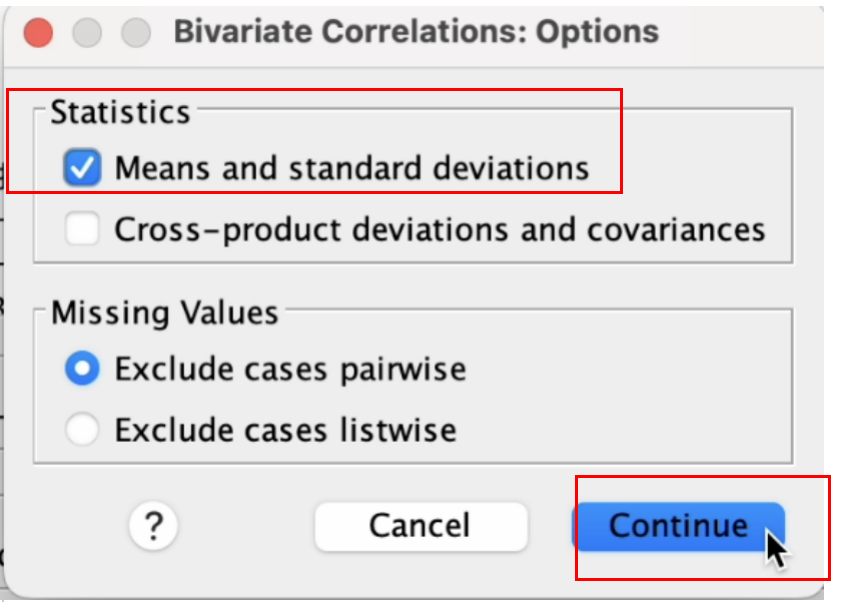
回到 Bivariate Correlations 窗口, 接着点选 Confidence Interval 按钮。 如 Figure 5 所示:
在弹出的 Bivariate Correlations: Confidence Interval 窗口中,点选 Estimate confidence interval of bivariate correlation parameter,然后按 Continue。 如 Figure 6 所示:
最后,回到 Bivariate Correlations 窗口,点选 OK 按钮,执行相关分析。 如 Figure 7 所示:
1.3.3 双变量相关分析SPSS报表解读
在SPSS输出视窗中,查看相关分析结果报表。
1.3.3.1 Descriptive statistics报表
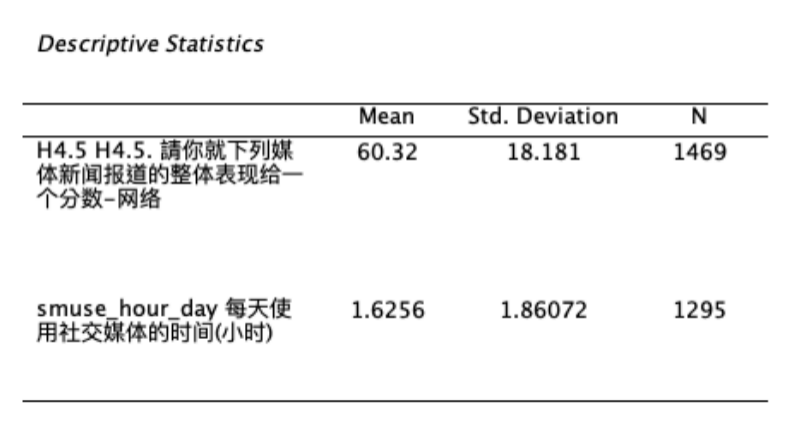
会呈现两个变量的平均数(Mean)、标准差(Std. Deviation)、以及样本数(N)。 如 Figure 8 所示:
1.3.3.2 Correlation报表
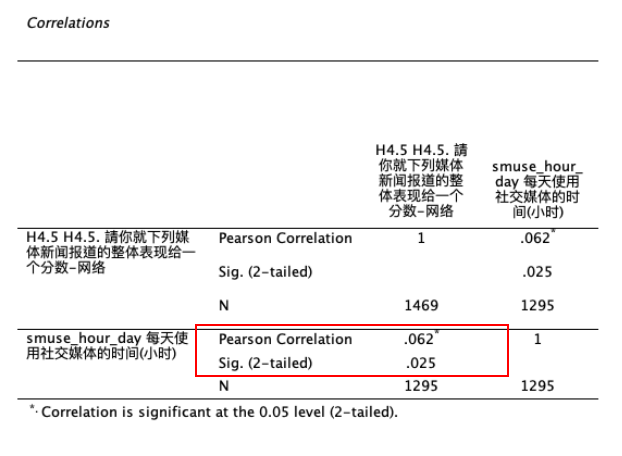
会呈现两个变量的皮尔森积差相关系数(Pearson Correlation)、显著性检验值(Sig. (2-tailed))、以及样本数(N)。 如 Figure 9 所示:
Correlations 报表显示, 两个变量彼此之间的相关系数(Pearson Correlation)=0.062,Sig值(即P值)=0.025 < 0.05,代表两变量之间的相关系数,如果推论到总体,有达到统计上的显著差异(看左下角或右上角即可)。
1.3.3.3 Confidence Intervals 报表
会呈现两个变量的相关系数的置信区间(CI Lower Bound与CI Upper Bound)。 如 Figure 10 所示:
Confidence Intervals 报表显示, 此一相关系数(Pearson Correlation),如果推论到总体,总体的相关系数会有95%的概率落在[0.008~0.116]这个置信区间(confidence interval)内。此一区间不包括0,所以总体的相关系数不太可能会等于0,有达到统计上的显著差异。

1.3.4 多变量相关分析
依照同样的操作程序,我们可以把 H4.1~H4.5这五个变量放到 Bivariate Correlations 方框内,然后按 OK。观察一下这五个变量彼此之间的关系。 如 Figure 11 所示:
一样会出现:
1.3.4.1 Descriptive Statistics 报表
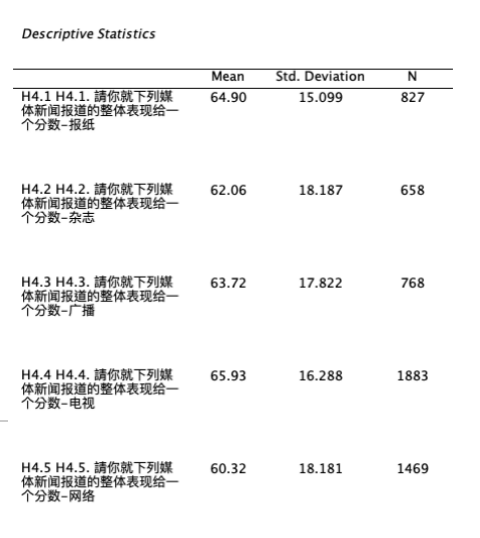
呈现五个变量的平均数、标准差和样本数。 如 Figure 12 所示:
1.3.4.2 Correlation 报表
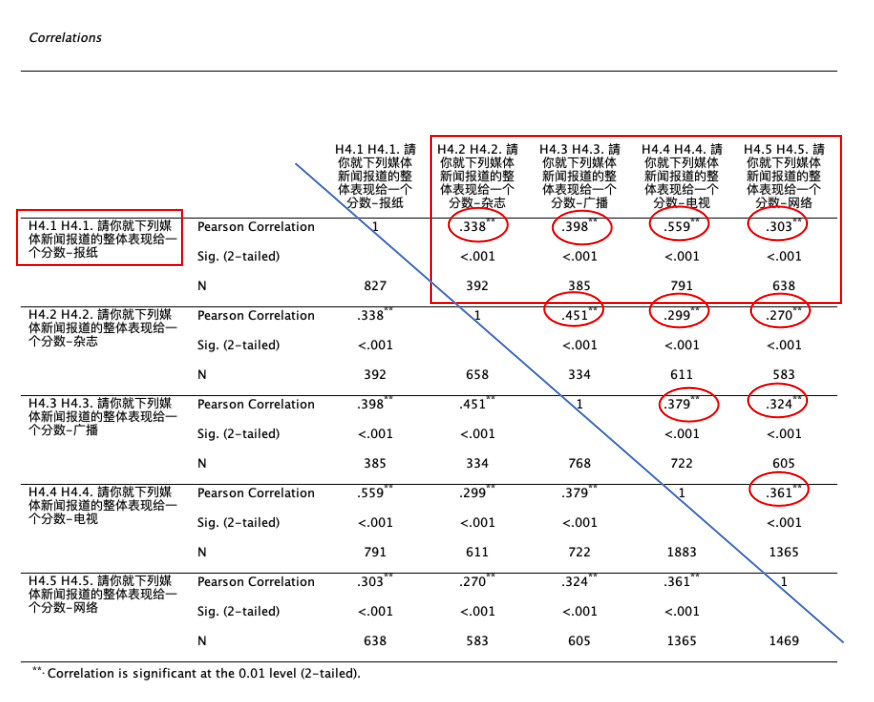
Correlations报表显示, 就 H4.1 而论,
H4.1(对报纸报道新闻的评价)与H4.4(对电视报道新闻的评价)的相关系数最高(\(Pearson Correlation=0.559\)),有达到统计上的显著差异(\(P< 0.001\))。其次是H4.3广播媒体(0.398)、再其次是H4.2杂志媒体(0.338),相关度最低的是H4.5网络媒体(0.303)。这些相关系数都有达到统计上的显著差异(\(P< 0.001\))。
其他变量之间的相关,可依此类推。这五个变量之间的相关系数,彼此之间都有达到统计上的显著差异(看左下角或右上角即可)。 如 Figure 13 所示:
2 单变量线性回归
2.1 基本概念图解
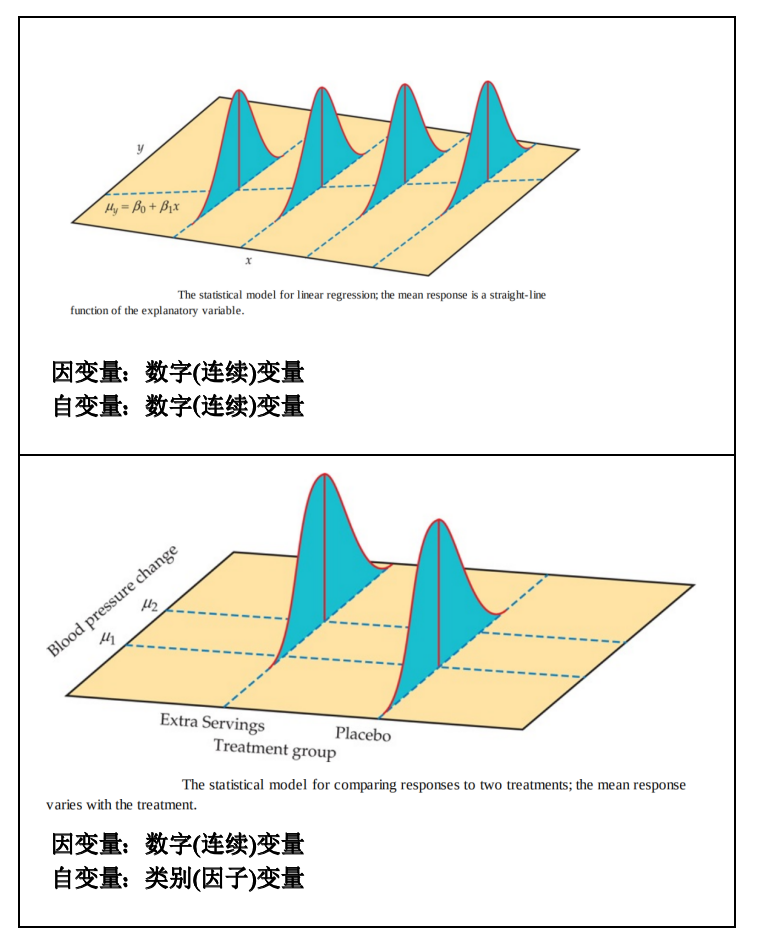
2.2 使用回归分析的目的
当我们想要去解释或预测某个现象(因变量)时,我们经常会使用回归分析,最常用的是 线性回归分析 (linear regression analysis)。线性回归分析的主要目的是要了解一个或多个自变量 (independent variable, iv) 对于因变量 (dependent variable, dv) 的解释力 (explanatory power),以及预测力 (predictive power),假设自变量与因变量之间系呈现一种线性关系。当自变量只有一个时,称为单变量(简单)线性回归;当自变量有二个或二个以上时,称为多变量线性回归。
2.3 数据准备 (TCS2015sc_Ch11_NoDummy.sav)
启动SPSS软件,进入主界面。导入包含因变量和自变量的数据档案(本例:TCS2015sc_Ch11_NoDummy.sav)。
2.4 SPSS操作:因变量(连续变量)~自变量(连续变量)
选择一个连续因变量: 例如:H4.5(请你就下列媒体新闻报道的整体表现给一个分数-网络); 也选择一个连续自变量, 例如: smuse_hour_day(每天使用社交媒体的时间-小时数)。
在SPSS中,选择
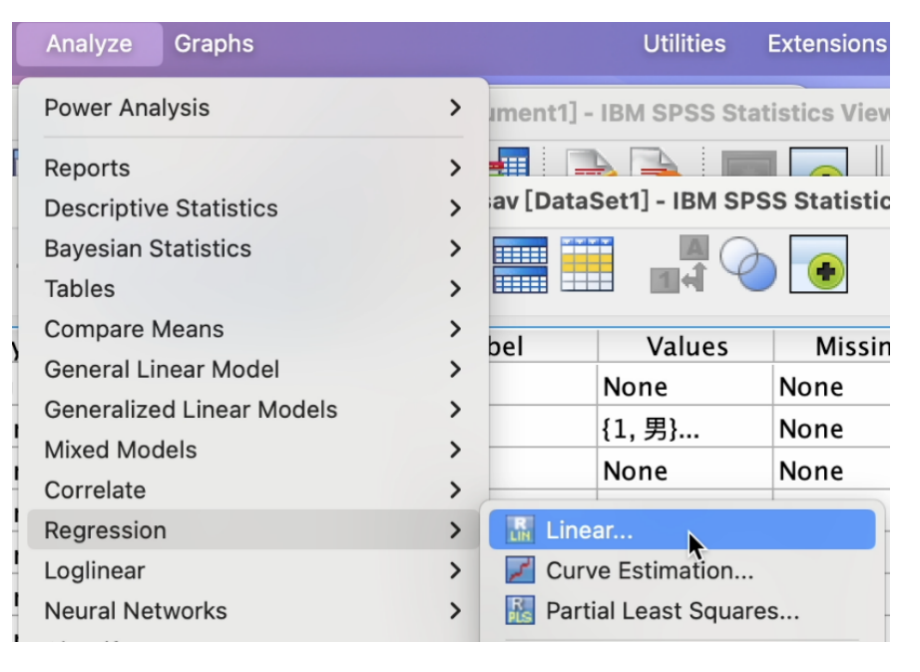
Analyze -> Regression -> Linear 如 Figure 15 所示:
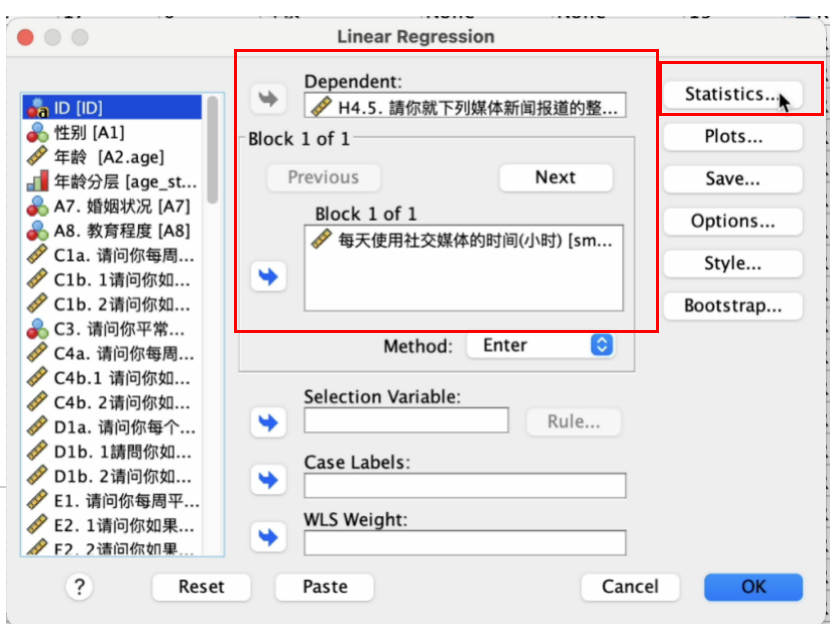
在弹出的 Linear Regression 窗口, 将 H4.5(请你就下列媒体新闻报道的整体表现给一个分数-网络)移到右边的 Dependent方框内; 将 smuse_hour_day(每天使用社交媒体的时间-小时数),移到右边的 Block 1 of 1 方框内。 继续点选Statistics按钮。 如 Figure 16 所示:
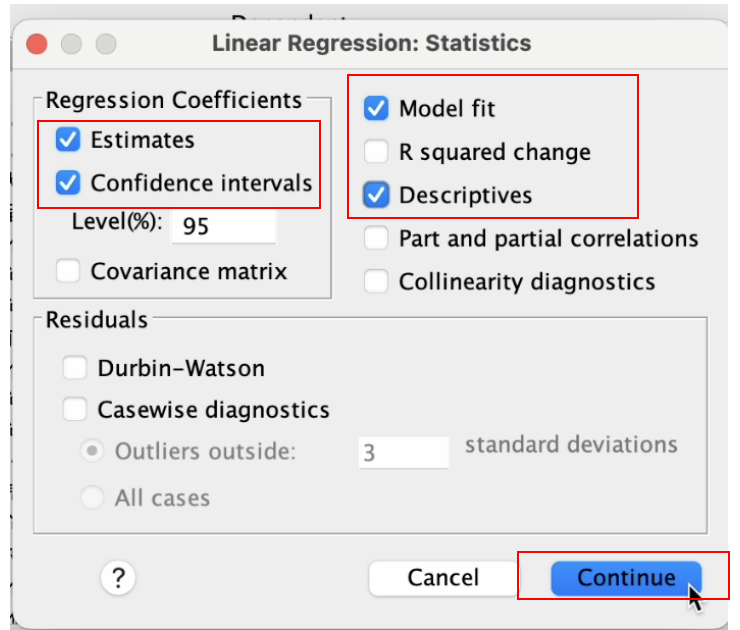
在弹出的 Linear Regression: Statistics窗口, 分别点选 Estimates, Confidence intervals,Model fit, 以及 Descriptive,然后按 Continue 。 如 Figure 17 所示:
回到 Linear Regression 窗口,点选 OK 如 Figure 18 所示:
在SPSS输出视窗中,查看相关分析结果报表。
2.4.1 Descriptive statistics报表
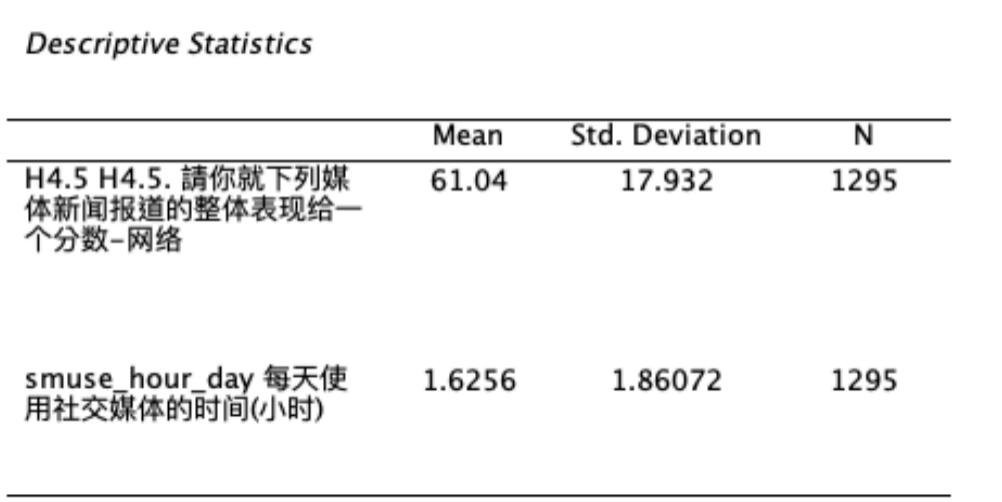
Descriptive statistics报表分别呈现因变量与自变量的平均数(Mean)、标准差(Std. Deviation)与样本数(N)。 如 Figure 19 所示:
2.4.2 Correlations报表
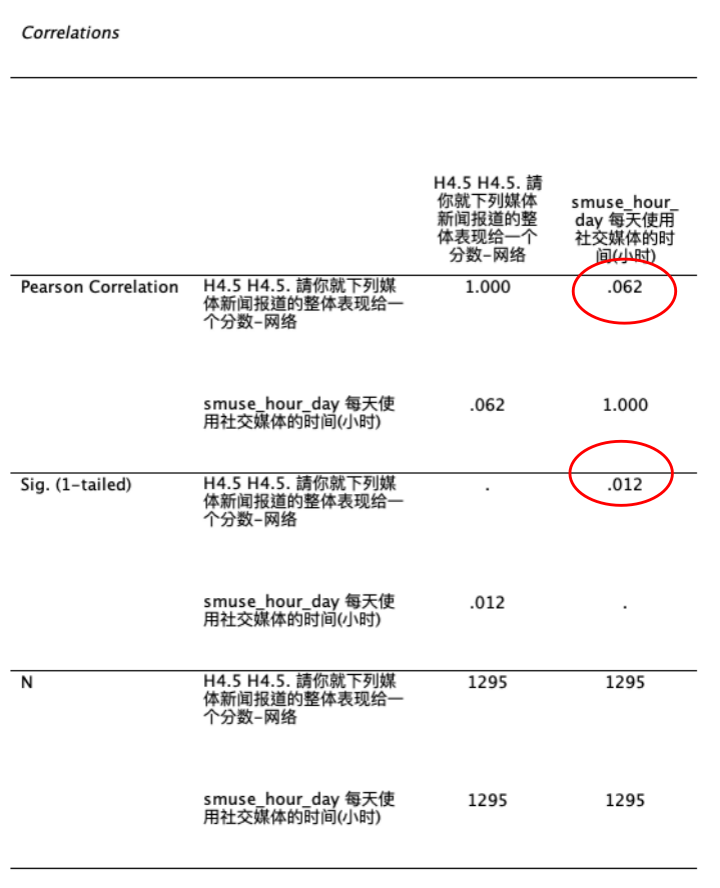
Correlations报表呈现两变量之间的相关系数=0.062,表示两变量之间有一定的相关(虽然相关系数很小), 且此一相关系数有达到统计上的显著差异(\(Sig.=0.012 < 0.05\))。 如 Figure 20 所示:
2.4.3 ANOVA 报表
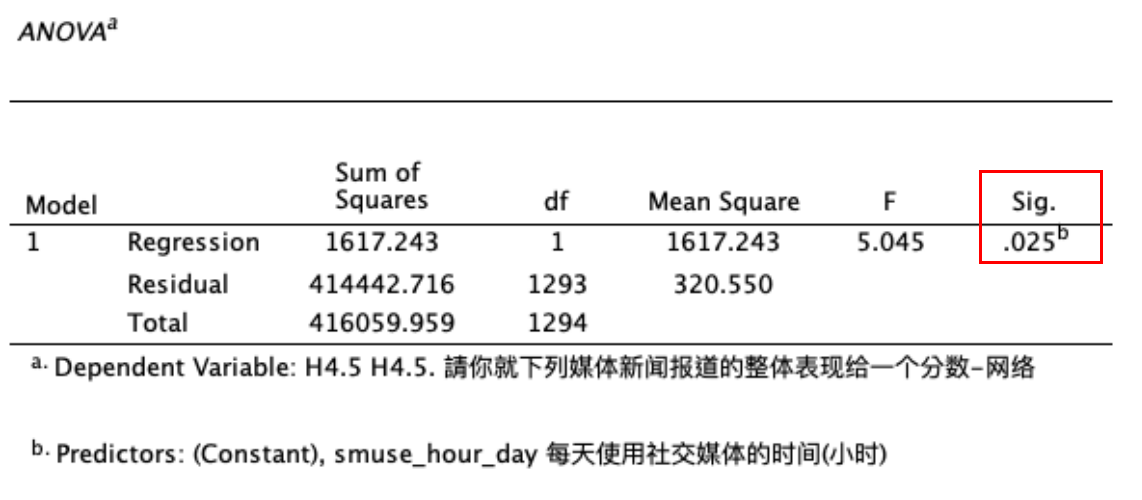
ANOVA报表显示,\(F=5.045,Sig.= 0.025 < 0.05\),表示自变量 smuse_hour_day 对于因变量H4.5,有一定程度的解释力。 如 Figure 21 所示:
2.4.4 Model Summary报表
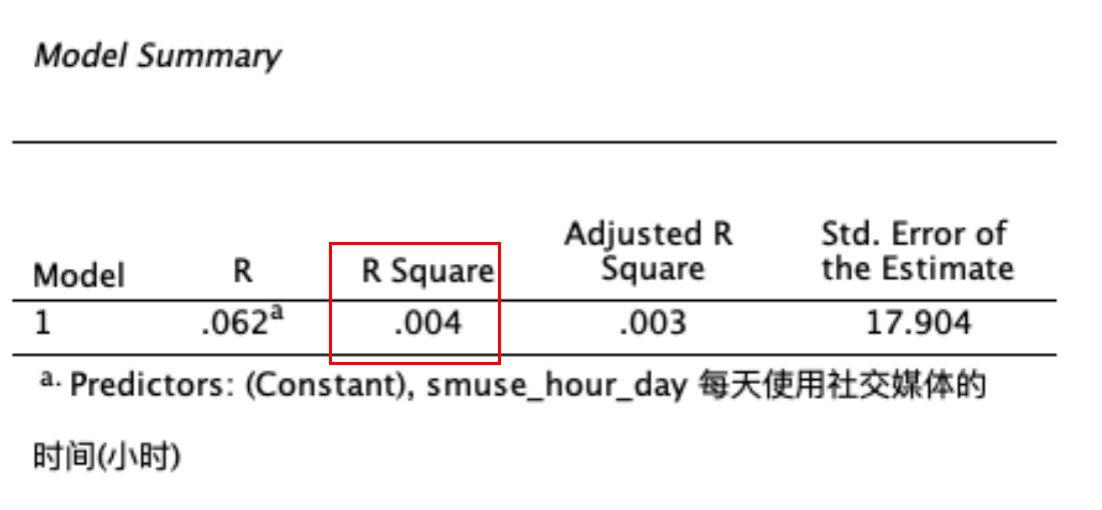
Model Summary报表显示,自变量 smuse_hour_day 对于因变量 H4.5 的总体解释力=0.004=0.4%(看R Square),解释力很小。 R Square的值介于0~1之间,数值愈大,解释力愈强。 如 Figure 22 所示:
Important
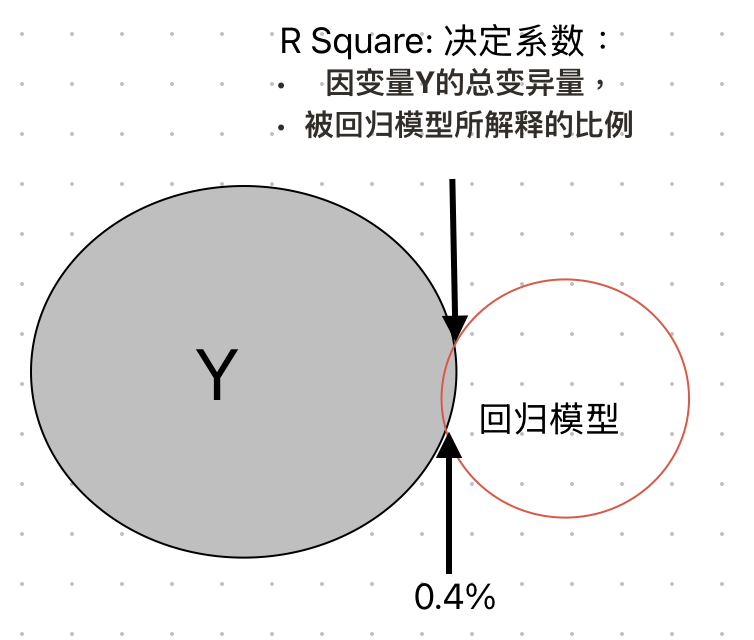
\(R^2\)(读音:R Square),代表:因变量\(Y\)的总变异量,被回归模型所解释的比例,如 Figure 23 所示(右图),
\(R^2\)概念图解
2.4.5 Coefficients报表
Coefficients报表可以显示自变量smuse_hour_day对于因变量H4.5的个别影响力。 如 Figure 24 所示:
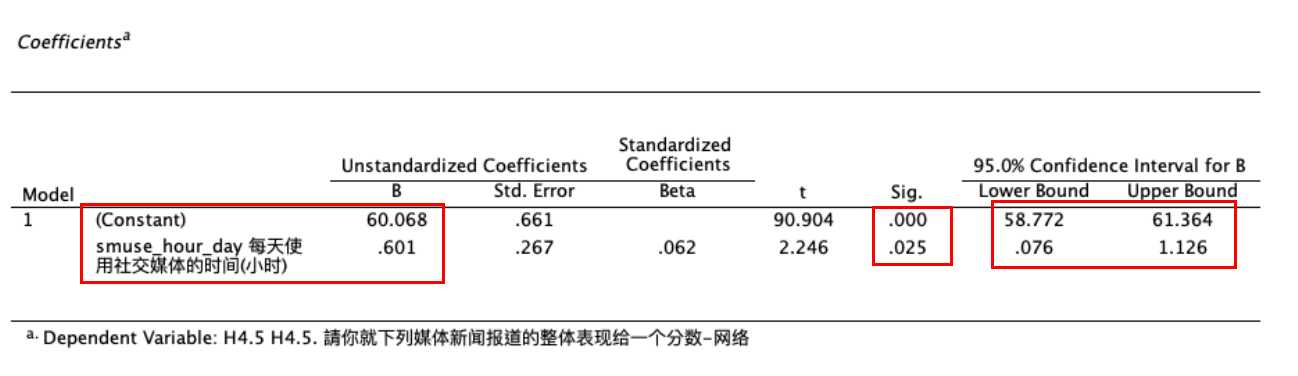
- 自变量的未标准化beta(Unstandardized Coefficients B)
Important
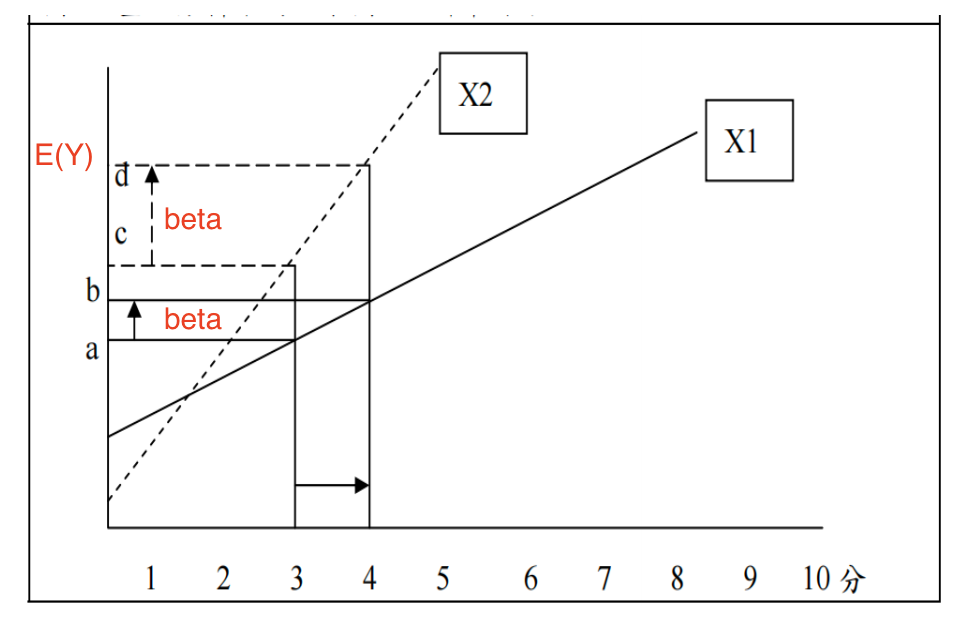
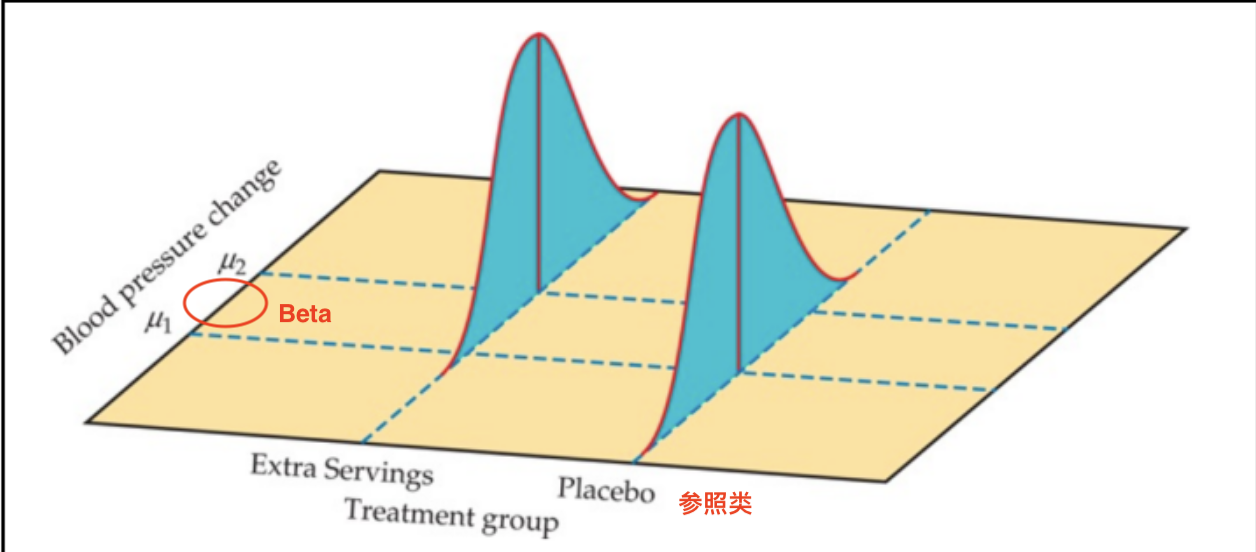
\(\beta\)(读音:\(beta\)),代表:自变量\(X\)每增加一个单位,因变量的预测平均数\(E(Y)\)所改变的量,如 Figure 25 所示(右图)。
\(\beta\)概念图解
本例,自变量 smuse_hour_day 对于因变量 H4.5 的未标准化beta=0.601,代表:民众每天使用社交媒体的时间(smuse_hour_day)每增加1小时,对于网络媒体新闻报道的评价(H4.5),平均来说,会增加0.601分。 此一个别影响力,经统计检验以及\(P\)值检验法得知,已达到统计上的显著差异(\(t=2.246, Sig.=0.025 < 0.05\))。 透过置信区间法(Confidence Interval)也可以得知, 如果同时间进行100次抽样调查,则会有95次的未标准化的beta落在\([0.076 ~ 1.126\)]之间,此一区间并未包括0。 即此一个别影响力,如果推论回总体,在95%置信水平下,其数值等于0的概率很低。
- 常数项(Constant),又称:截距(Intercept)
Important
意指: 当模型内所有自变量\(X_i\)都等于0时,因变量\(Y\)的预测平均数所在位置。
本例,Constant=60.068,代表: “当每天使用社交媒体的时间为0小时(即都不使用社交媒体),民众对于网络媒体报道新闻的评价的平均数=60.068”。
此一常数项,经统计检验以及\(P\)值检验法得知,已达到统计上的显著差异(\(t=90.904, Sig.=0.000 < 0.05\))。 透过置信区间法(Confidence Interval)也可以得知, 如果同时间进行100次抽样调查,则会有95次的未标准化beta落在\([58.77 ~ 61.36]\)之间,此一区间并未包括0。 即此一常数项,如果推论回总体,在95%置信水平下,其数值等于0的概率很低(常数项不太可能为0)。
2.4.6 线性回归方程式(Regression Equation)
单变量线性回归方程式的基本形式为:
Important
\[ E(Y) = a + bX \]
其中,
\(E(Y)\):代表因变量Y的预测平均数;
\(a\):代表常数项(Constant);
\(b\):代表自变量X的未标准化beta;
\(X\):代表自变量X。
例如:根据Coefficients报表(Figure 24 ), 我们得到:
\(a\):60.068
\(b\):0.601
\(X\):smuse_hour_day
因此,本例的线性回归方程式:
\[ E(Y) = 60.068 + 0.601X \]
其中,
\(E(Y)\):代表因变量H4.5(请你就下列媒体新闻报道的整体表现给一个分数-网络)的预测平均数。
\(X\):代表自变量smuse_hour_day(每天使用社交媒体的时间-小时数)。
通过此一线性回归方程式,我们可以预测不同使用社交媒体时间的民众,对于网络媒体新闻报道的评价平均数。
例如:假设有一群人每天使用社交媒体的时间为5小时(X=5),则我们可以预测这群人对网络媒体新闻报道的评价平均数为:
\[ E(Y) = 60.068 + 0.601\times(5) = 63.073 \]
也就是说,假设有一群人每天使用社交媒体的时间为5小时,则我们可以预测这群人对网络媒体新闻报道的评价平均数约为63.073分。
2.4.7 线性回归图的SPSS操作
在SPSS视窗中,选择: Graphs -> Legacy Dialogs ->Scatter/Dot。 如 Figure 26 所示
在弹出的 Scatter/Dot 窗口,选择 Simple Scatter,然后按 Define 按钮。 如 Figure 27 所示:
在弹出的 Simple Scatterplot 窗口, 将 H4.5(请你就下列媒体新闻报道的整体表现给一个分数-网络)移到右边的 Y Axis方框内; 将 smuse_hour_day(每天使用社交媒体的时间-小时数),移到右边的 X Axis 方框内。 然后按 OK 按钮。 如 Figure 28 所示:
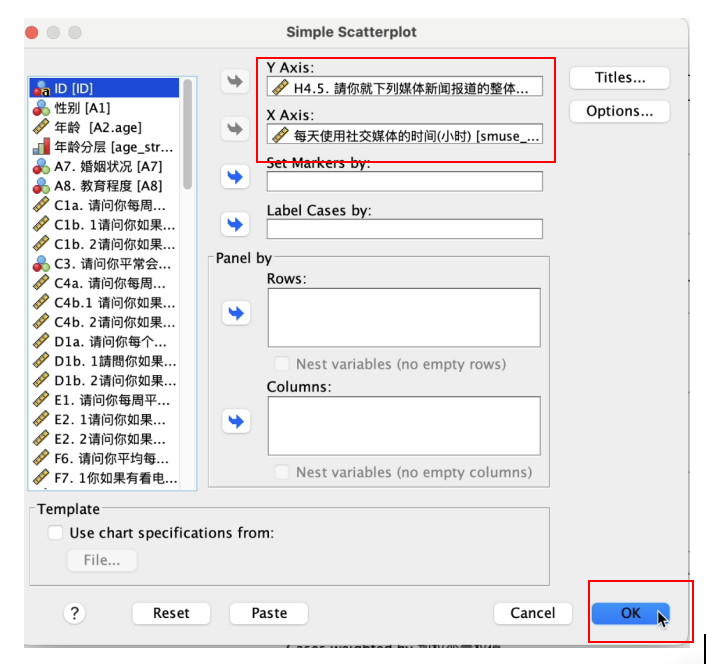
在SPSS输出视窗中,查看散布图(图形),并用鼠标左键双击散布图。 如 Figure 29 所示:
在弹出的 Chart Editor 窗口,将鼠标移到快捷图标 并停留一下子,会出现 Add Fit Line at Total字样, 点下去。 如 Figure 30 所示:
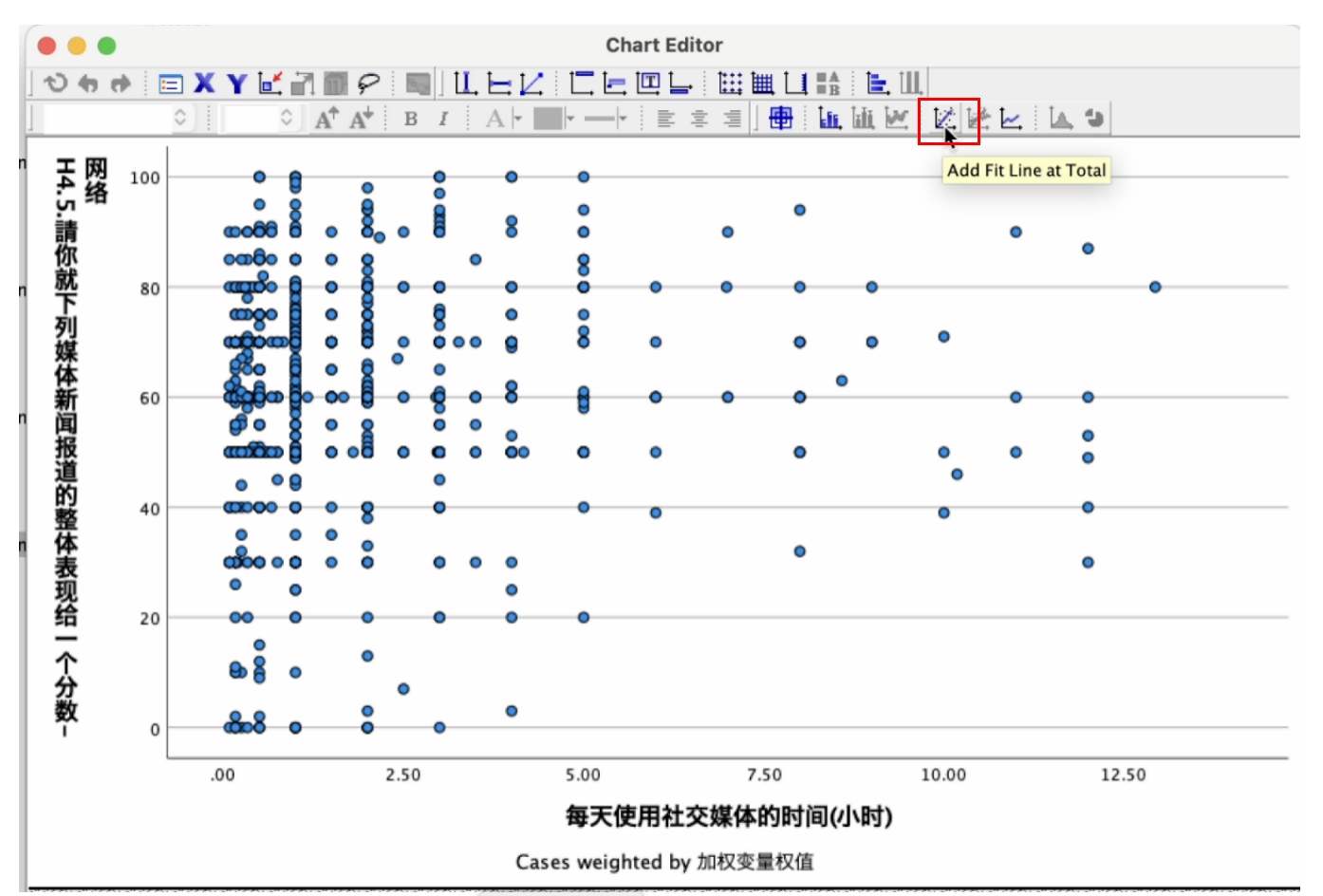
在弹出的 Properties 窗口。 在 Fit Method 处,SPSS默认呈现 Linear, 这是我们要的,继续点击 Close按钮。 如 Figure 31 所示:
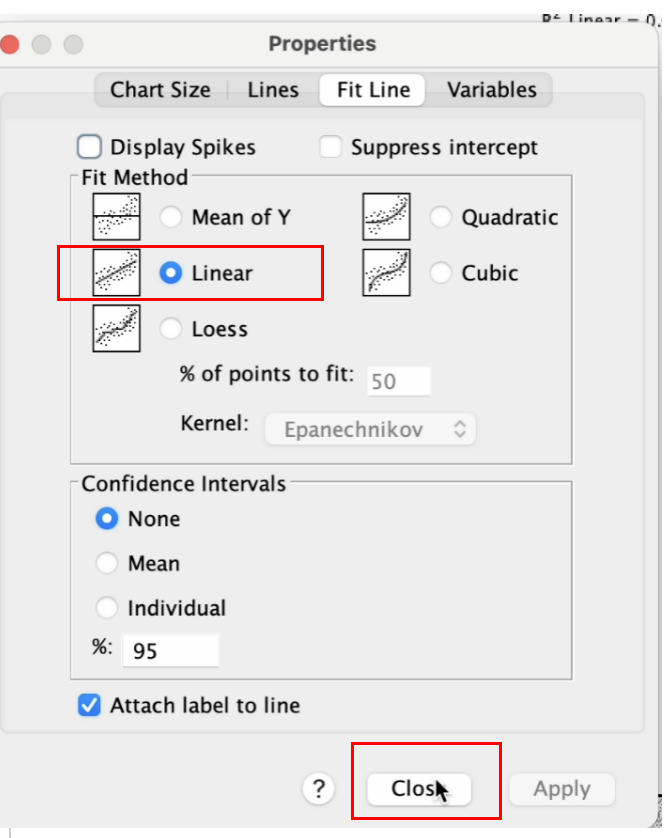
回到 Chart Editor窗口, 此时会出现 回归线、回归方程式以及\(R^2\)值。 如 Figure 32 所示:
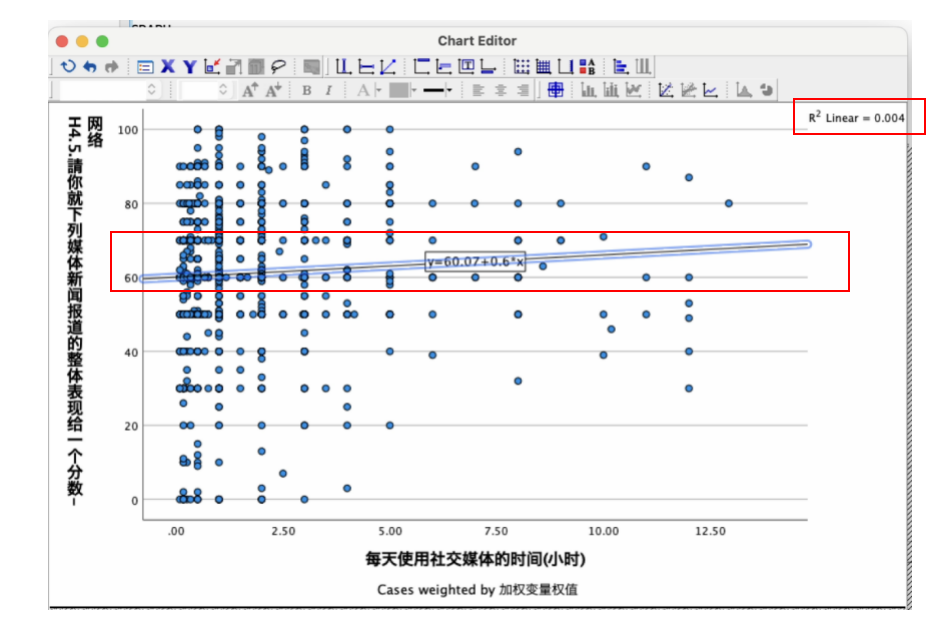
最后,关闭 Chart Editor 窗口, 在图形范围外,用鼠标左键随意再点一下,一个散布图+回归线的图,就会出现在你的 Output 窗口了。
2.5 SPSS操作:因变量(连续变量) ~自变量(类别因子变量)
选择一个连续因变量:例如: H4.5(请你就下列媒体新闻报道的整体表现给一个分数-网络); 也选择一个类别因子自变量, 例如: age5(年龄五分类)。
2.5.1 制造虚拟变量(哑变量)(Dummy Variable)
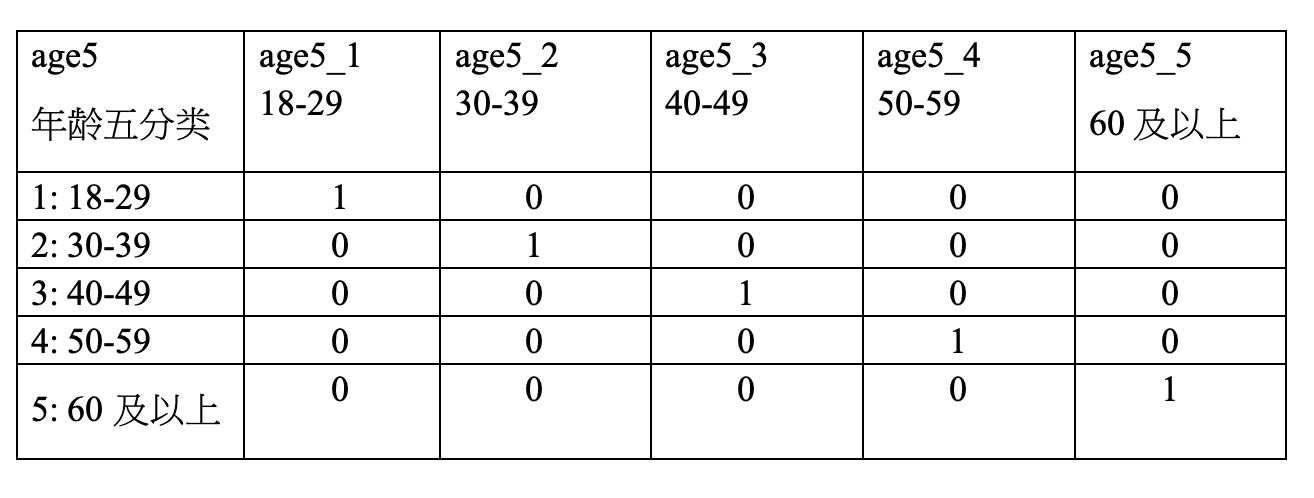
類別自变量在投入回归分析时,不能直接投入,必须先将类别变量转换为虚拟变量(哑变量)。以 age5变量为例,有五类,所以我们将 “类别”转换为”变量”,制造五个虚拟变量。 如 Table 1 所示:
在SPSS中,要如何制作这些虚拟变量呢?
打开SPSS,在视窗中,选择: Transform -> Create Dummy Variables 如 Figure 33 所示:
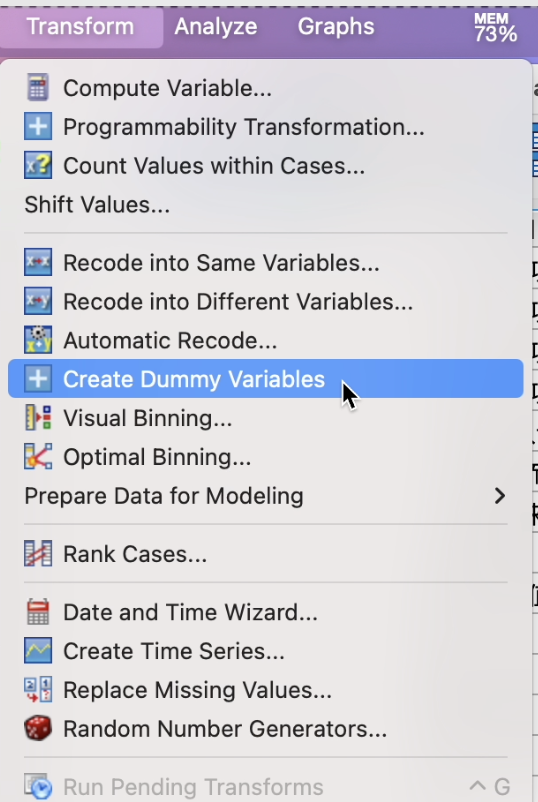
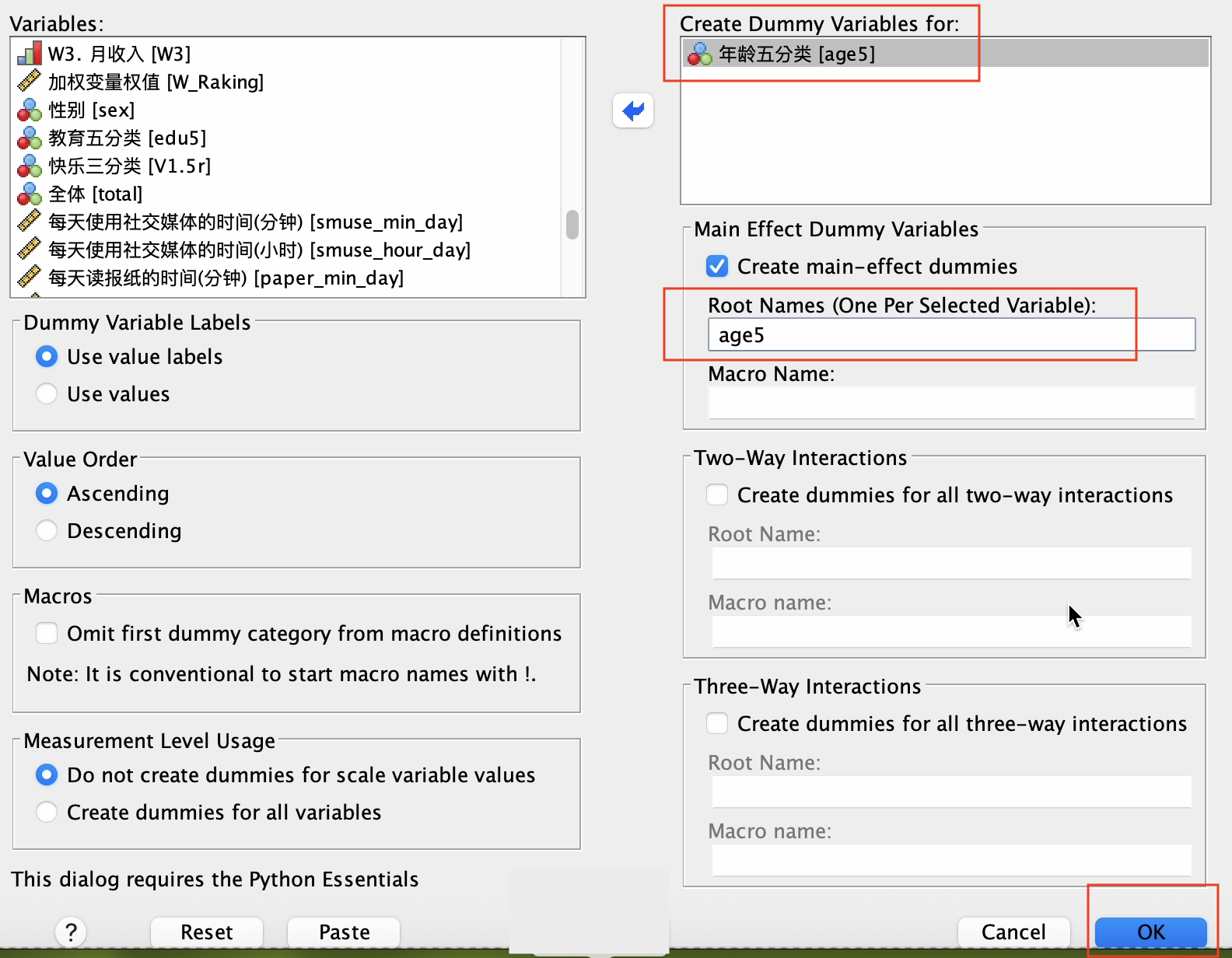
在弹出的 Create Dummy Variables 窗口, 将 age5(年龄五分类)移到右边的 Create Dummy Variables for方框内; 在 Main Effect Dummy Variables 项目下的 Root Names 方框,填入分析的自变量(类别因子变量) age5; 然后按 OK 按钮。 如 Figure 34 所示:
此时,SPSS会自动在数据视窗(Data View)中,制造出五个虚拟变量(Dummy Variables),分别为: age5_1(label:age5=18-29)、 age5_2(label:age5=30-39)、 age5_3(label:age5=40-49)、 age5_4(label:age5=50-59)、以及 age5_5(label:age5=60及以上) 如 Figure 35 所示:

2.5.2 执行线性回归分析
虚拟变量制造成功后,就可以继续进行线性回归分析。 但要注意的是,在自变量部分,我们只能选择其中的k-1个虚拟变量进入回归模型(其中k为类别因子变量的类别数), 例如:age5变量有5类(5个水平),先前已将age5变量制造成五个虚拟变量,在执行回归分析时,我们只能放进5-1(=4)个虚拟变量进入回归模型,没有放进的那一类,称为参照组(reference group),会自动被SPSS当作基准组(baseline group)。
我们通常将第1类或最后1类作为参照组(baseline group),本例,我们将age5_5(label:age5=60及以上)作为参照组(baseline group),不放进回归模型中。
另外,要选择一个连续因变量。本例,仍选择:H4.5(请你就下列媒体新闻报道的整体表现给一个分数-网络)。
SPSS操作步骤如下:
Analyze -> Regression -> Linear 如 Figure 36 所示:
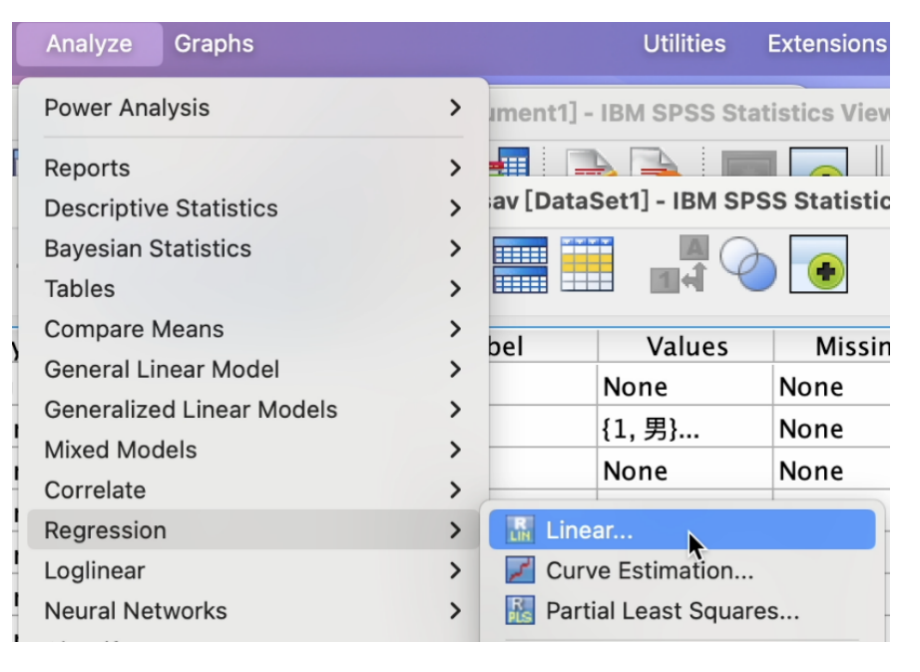
在弹出的 Linear Regression 窗口, 将 H4.5(请你就下列媒体新闻报道的整体表现给一个分数-网络)移到右边的 Dependent方框内; 将 四个虚拟变量: age5_1(label:age5=18-29)、 age5_2(label:age5=30-39)、 age5_3(label:age5=40-49)、以及 age5_4(label:age5=50-59), 移到右边的 Block 1 of 1 方框内。 继续点选Statistics按钮。 如 Figure 37 所示:
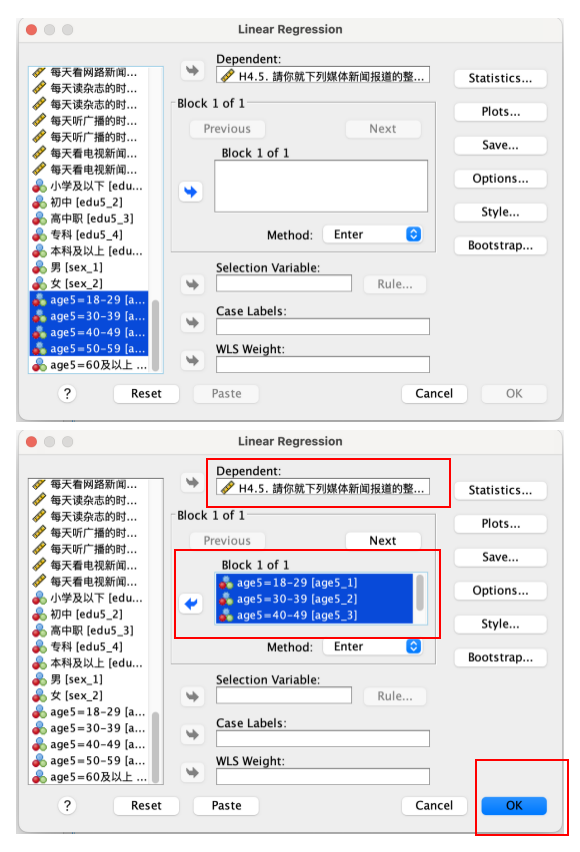
Statistics的设置,同前。 如 Figure 38 所示:
回到 Linear Regression 窗口,点选 OK 如 Figure 39 所示:
在SPSS输出视窗中,查看回归分析结果报表。
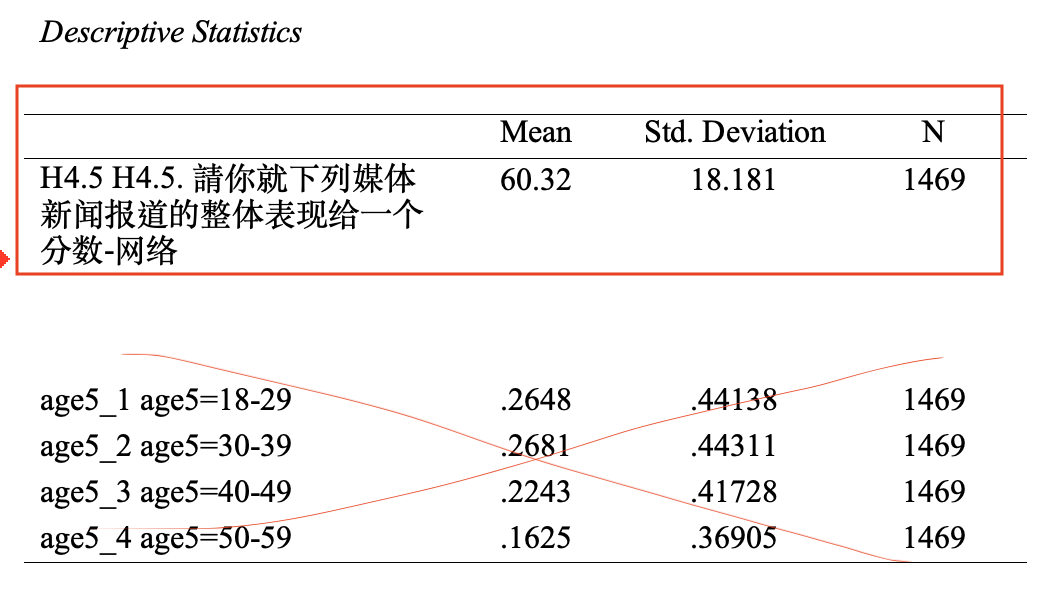
2.5.3 Descriptive statistics报表
Descriptive statistics报表,我们只要看因变量的平均数(Mean)、标准差(Std. Deviation)与样本数(N)即可。 如 Figure 40 所示:
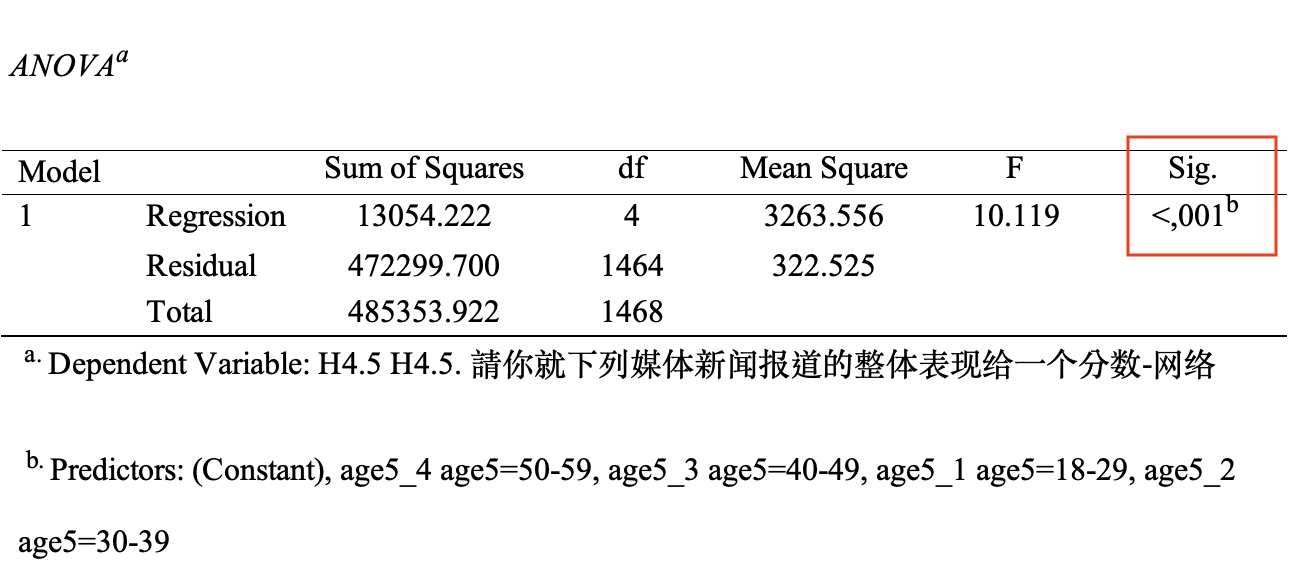
2.5.4 ANOVA 报表
ANOVA报表显示,\(F=10.119,Sig. < 0.001\),表示4个虚拟自变量 age5_1, age5_2, age5_3,age5_4 对于因变量H4.5, 有一定程度的解释力。如 Figure 41 所示:
2.5.5 Model Summary报表
Model Summary报表显示,4个虚拟自变量 age5_1, age5_2, age5_3,age5_4 对于因变量 H4.5 的总体解释力=0.027=2.7%(看R Square),虽有解释力,但解释力不高。 如 Figure 42 所示:
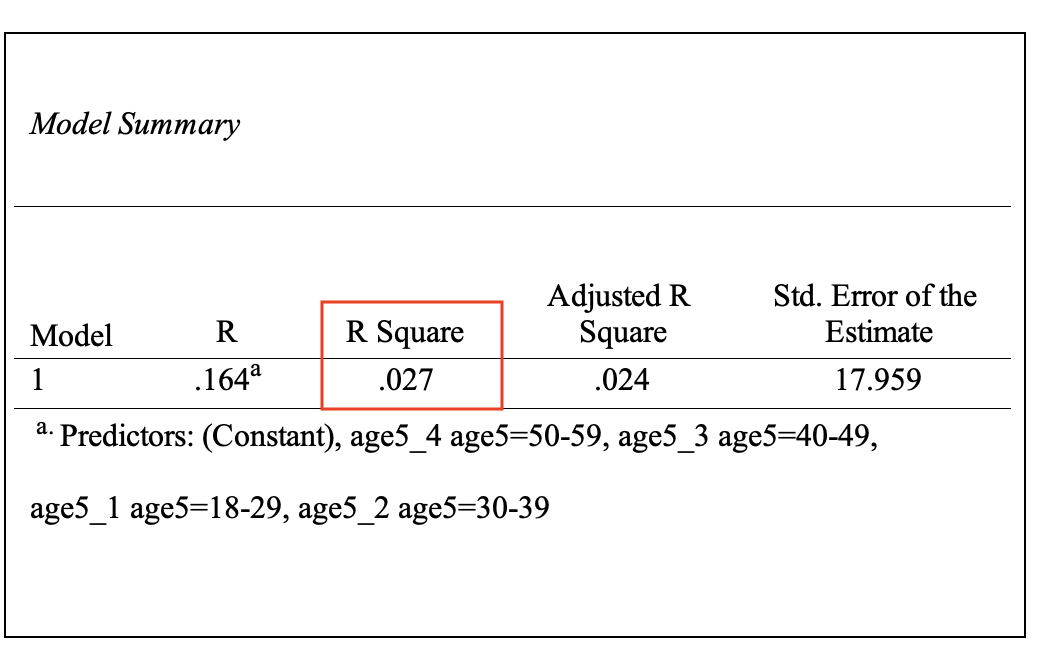
2.5.6 Coefficients报表
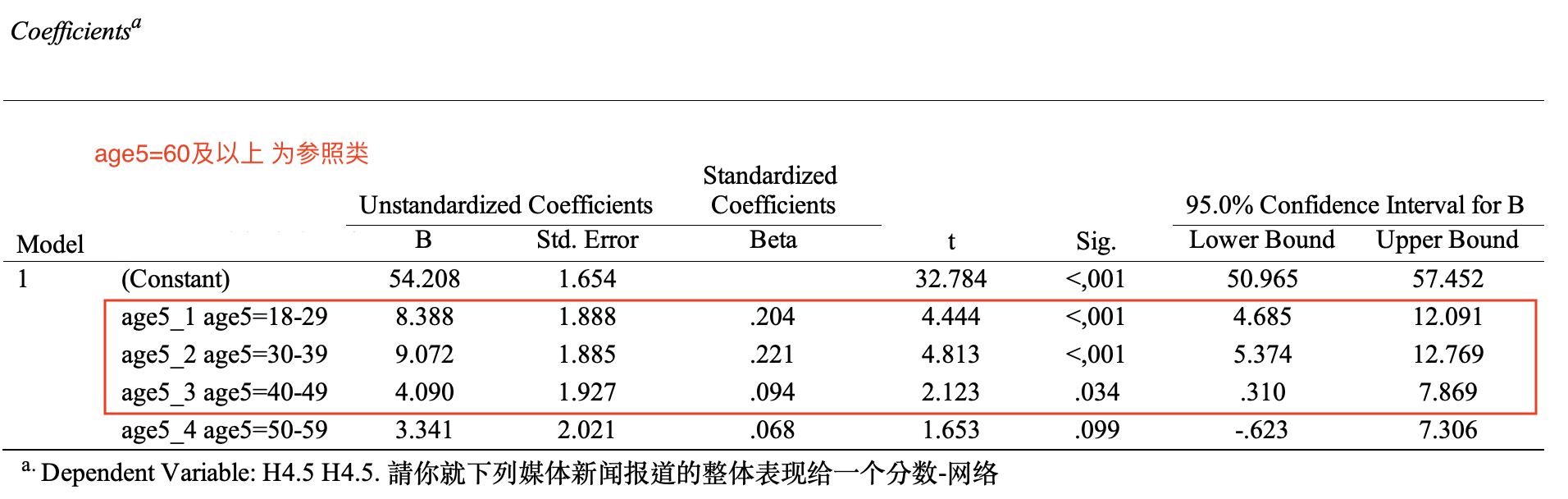
Coefficients报表可以显示四个虚拟自变量 age5_1, age5_2, age5_3,age5_4 对于因变量H4.5的个别影响力。 如 Figure 43 所示:
当自变量为类别变量时,其回归系数(coefficient)的意涵是:
Important
该自变量X相较于参照类,在因变量的预测平均数,所改变的量。
具体来说:
18-29对应的未标准化beta(Unstandardized B)= 8.388, 这表示:就调查样本来说,18-29岁民众相较于60及以上民众(参照类),对于网络媒体报道新闻的评价分数,平均来说,高了 8.388分。(\(Sig. < 0.001\),95%CI =\([+4.685 ~ +12.091]\)之间,不包括0)。 这个意思是说,如果推论回总体,则18-29岁民众对于网络媒体报道新闻的评价,有很大的概率不会等于0,且其和60岁及以上民众对于网络媒体报道新闻的评价相较,两者之间有显著的差异。
30-39对应的未标准化beta(Unstandardized B)= 9.072, 这表示:就调查样本来说,30-39岁民众相较于60及以上民众(参照类),对于网络媒体报道新闻的评价分数,平均来说,高了 9.072分。(\(Sig.< 0.001\),95%CI =\([ +5.374 ~ +12.769]\)之间,不包括0。 这个意思是说,如果推论回总体,则30-39岁民众对于网络媒体报道新闻的评价,有很大的概率不会等于0,且其和60岁及以上民众对于网络媒体报道新闻的评价相较,两者之间有显著的差异。
40-49对应的未标准化beta(Unstandardized B)= 4.090, 这表示:就调查样本来说,40-49岁民众相较于60及以上民众(参照类),对于网络媒体报道新闻的评价分数,平均来说,高了 4.090分。(\(Sig.= 0.034<0.05\),95%CI =\([ +0.310 ~ +7.869]\)之间,不包括0。 这个意思是说,如果推论回总体,则40-49岁民众对于网络媒体报道新闻的评价,有很大的概率不会等于0,且其和60岁及以上民众对于网络媒体报道新闻的评价相较,两者之间有显著的差异。
50-59对应的未标准化beta(Unstandardized B)= 3.341, 这表示:就调查样本来说,50-59岁民众相较于60及以上民众(参照类),对于网络媒体报道新闻的评价分数,平均来说,高了 3.341分。(但\(Sig.= 0.099 > 0.05\),95%CI =\([ -0.623 ~ +7.306]\)之间,有包括0。这个意思是说,如果推论回总体,则50-59岁民众对于网络媒体报道新闻的评价,有不小的概率会等于0,且其和60岁及以上民众对于网络媒体报道新闻的评价相较,两者之间没有显著的差异。
2.5.7 模型预测
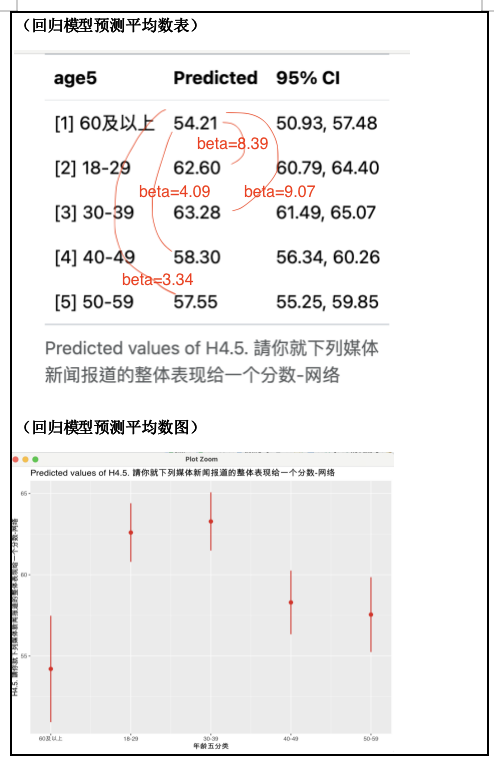
依据 Figure 43 不同年龄层对于Y(网络媒体报道新闻的评价)的\(\beta(beta)\)系数,我们可以计算不同年齡层对于Y的预测平均数,计算如下:
\[ E(Y) = a + bX \]
\[ E(Y) = a + b_{1829} \times age5_{1829}+ b_{3039} \times age5_{3039}+ b_{4049} \times age5_{4049}+b_{5059} \times age5_{5059} \\ \]
就18-29来说,其对于Y的预测平均数:
\[ E(Y) = 54.208 + 8.388 \times 1 + 9.072 \times 0 + 4.090 \times 0 + 3.341 \times 0 \\ =54.208 + 8.388 \\ =62.596 \]
就30-39来说,其对于Y的预测平均数:
\[ E(Y) = 54.208 + 8.388 \times 0 + 9.072 \times 1 + 4.090 \times 0 + 3.341 \times 0 \\ =54.208 + 9.072 \\ =63.28 \]
就40-49来说,其对于Y的预测平均数:
\[ E(Y) = 54.208 + 8.388 \times 0 + 9.072 \times 0 + 4.090 \times 1 + 3.341 \times 0 \\ =54.208 + 4.090 \\ =58.298 \]
就50-59来说,其对于Y的预测平均数:
\[ E(Y) = 54.208 + 8.388 \times 0 + 9.072 \times 0 + 4.090 \times 0 + 3.341 \times 1 \\ =54.208 + 3.341 \\ =57.549 \]
就60及以上来说,其对于Y的预测平均数:
\[ E(Y) = 54.208 + 8.388 \times 0 + 9.072 \times 0 + 4.090 \times 0 + 3.341 \times 0 \\ =54.208 + 0 \\ =54.208 \]
如 Figure 45 所示(R绘图):
SPSS操作视频
附记
阅读本讲义,另请参阅:王 & 郭 (2022, pp. 224–226, 231–233)
王晓华., & 郭良文. (2022). 传播学研究方法. 高等教育出版社.
样本统计量计算公式(参考)
相关系数(Pearson Correlation Coefficient)
[理论公式]:
\[ \begin{align} r = \frac{Cov(X,Y)}{\sigma_X \cdot \sigma_Y} \end{align} \]
\(Cov(X,Y)\): \(X\) 与 \(Y\) 的协方差(共变数)(covariance)
\(\sigma_X\):\(X\) 的标准差
\(\sigma_Y\):\(Y\) 的标准差
\(\sigma_X \cdot \sigma_Y\):\(X\) 与 \(Y\) 的标准差乘积
[计算公式]:
\[ r = \frac{\sum_{i=1}^{n} (X_i - \bar{X})(Y_i - \bar{Y})} {\sqrt{\sum_{i=1}^{n} (X_i - \bar{X})^2} \cdot \sqrt{\sum_{i=1}^{n} (Y_i - \bar{Y})^2}} \]
\(n\): 样本大小
\(X_i\): 第 \(i\) 个观测值在变量 \(X\) 的数值
\(\bar{X}\):变量 \(X\)的 平均数
\(Y_i\): 第 \(i\) 个观测值在变量 \(Y\) 的数值
\(\bar{Y}\):变量 \(Y\)的 平均数
\((X_i - \bar{X})(Y_i - \bar{Y})\): 第 \(i\) 个观测值在\(X\)变量的数值减去\(X\)的平均数,与 该观察值在\(Y\)变量的数值减去\(Y\)的平均数, 两者之乘积(会得到一个面积)
\(\sum_{i=1}^{n} (X_i - \bar{X})(Y_i - \bar{Y})\): 所有观测值的乘积面积总和
\(\sqrt{\sum_{i=1}^{n} (X_i - \bar{X})^2}\):\(X\) 的标准差
\(\sqrt{\sum_{i=1}^{n} (Y_i - \bar{Y})^2}\):\(Y\) 的标准差
\(\sqrt{\sum_{i=1}^{n} (X_i - \bar{X})^2} \cdot \sqrt{\sum_{i=1}^{n} (Y_i - \bar{Y})^2}\):\(X\) 与 \(Y\)的标准差乘积
以 Figure 13 中,H4.1与H4.4变量为例,两变量之间的相关系数 \(Pearson's\) \(r\)=0.559
计算方法如下(使用 R ):
载入数据档
1.排除变量的缺失值(只限定在H4.1与H4.4变量皆有值的样本)
- 计算x, y变量各自的平均数
- 计算分子:协方差(共变数)
- 计算分母:标准差乘积
- \(Pearson's\) \(r\) 相关系数
[1] 0.5532841相关系数 r = 0.5532841 与前述相关系数0.559相同ANOVA 报表中,
F value
F检验统计量的计算公式:
\[ \begin{align} F &= \frac{SSR/df_{regression}} {SSE/df_{residual}}=\frac{MSR}{MSE}\\ \end{align} \]
- SSR(Sum of Squares Regression 回归平方和):回归模型所 能解释的变异。
计算公式如下:
\[ SSR = \sum_{i=1}^{n} (\hat{Y}_i - \bar{Y})^2 \]
内涵:回归模型预测值相对于总体均值所能解释的变异程度
其中:
\(\hat{Y}_i\):自变量\(X\)在第i个数值时对于因变量\(Y\)的预测平均数
\(\bar{Y}\):因变量\(Y\)的平均数
- SSE(Sum of Square Error 误差平方和):回归模型无法 解释的变异
计算公式如下:
\[ SSE = \sum_{i=1}^{n} (Y_i - \hat{Y}_i)^2 \] 其中:
\(Y_i\):因变量\(Y\)在自变量第i个观测值的数值
\(\hat{Y}_i\):自变量\(X\)在第i个数值时对于因变量\(Y\)的预测平均数
- 自由度(degree of freedom, df):
分为两部分: 回归模型的自由度(\(df_{regresion}\))与残差的自由度(\(df_{residual}\))
\(df_{regresion}\):,其值等于自变量个数(K),即:
\[ df_{regresion}= k \]
\(df_{residual}\):残差的自由度,其值等于样本数(n)减去自变量个数(K)再减去1,即:
\[ df_{residual}= n - k - 1 \]
- SST(Sum of Square Total 总平方和):
\[ SST = SSR + SSE = \sum_{i=1}^{n} (Y_i - \bar{Y})^2 \]
以 Figure 21 中ANOVA报表的单变量线性回归分析为例,\(F=5.045\),计算方法如下:
1.计算SSR(回归平方和)
\[ SSR = 1617.243 \]
2.计算SSE(误差平方和)
\[ SSE = 414442.716 \]
3.计算自由度
\[ df_{regresion}= k = 1 \]
\[ \begin{align} df_{residual}&= n - k - 1 \\ &= 1295 - 1 - 1 \\ &= 1293 \end{align} \]
4.计算MSR与MSE
\[ MSR = 1617.243 / 1 = 1617.243 \]
\[ MSE = 414442.716 / 1293 = 320.550 \]
5.计算F检验统计量
\[ F = 1617.243 / 320.550 = 5.045 \]
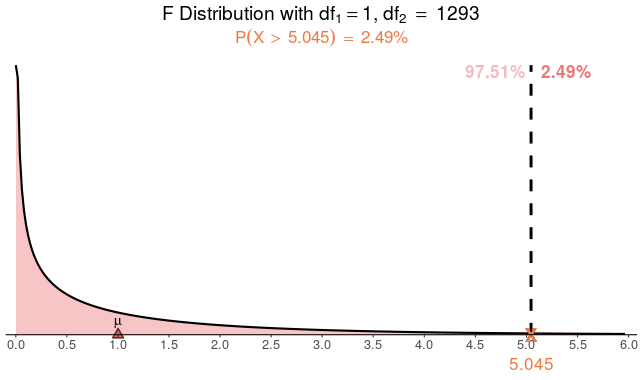
当 \(F=5.045\) 时,查阅 \(F\) 分配表(或使用统计软件),可得 \(P\) 值为 2.49% = 0.0249 = 0.025 < 0.05, 如 Figure 46 所示,
因此, smuse_hour_day 对于因变量 H4.5 有显著的解释力。
决定系数(R Square)
决定系数(\(R^2\))的计算公式:
\[ \begin{align} R^2 = \frac{SSR}{SST} \end{align} \]
以 Figure 22 中的 \(R^2\) 报表为例,\(R^2=0.004\), 计算方法如下:
\[ \begin{align} R^2 &= \frac{SSR}{SST}\\ &= \frac{1617.243}{416059.959} \\ &= 0.003887 \approx 0.004 \end{align} \]
线性回归系数(beta)
自变量 \(X\) 对于因变量 \(Y\) 的线性回归系数(\(beta\)),
[理论公式]:
\[ \begin{align} beta = \frac{Cov(X,Y)}{Var(X)} \end{align} \]
\(Cov(X,Y)\): \(X\) 与 \(Y\) 的协方差(共变数)(covariance)
\(Var(X)\):\(X\) 的方差(变异数)(variance)
[计算公式]:
\[ beta = \frac{\sum_{i=1}^{n} (X_i - \bar{X})(Y_i - \bar{Y})} {\sum_{i=1}^{n} (X_i - \bar{X})^2} \] \(n\): 样本大小
\(X_i\): 第 \(i\) 个观测值在变量 \(X\) 的数值
\(\bar{X}\):变量 \(X\)的 平均数
\(Y_i\): 第 \(i\) 个观测值在变量 \(Y\) 的数值
\(\bar{Y}\):变量 \(Y\)的 平均数
\((X_i - \bar{X})(Y_i - \bar{Y})\): 第 \(i\) 个观测值在\(X\)变量的数值减去\(X\)的平均数,与该观察值在\(Y\)变量的数值减去\(Y\)的平均数, 两者之乘积(会得到一个面积)
\(\sum_{i=1}^{n} (X_i - \bar{X})(Y_i - \bar{Y})\): 所有观测值的乘积面积总和
\(\sum_{i=1}^{n} (X_i - \bar{X})^2\):\(X\)的方差(变异数)(variance)
以 mydata数据档中的 smuse_hour_day 与 H4.5 变量为例, 使用 smuse_hour_day变量预测 H4.5 变量, 在未加权情况下,smuse_hour_day变量的线性回归系数 \(beta\)=0.5308
Call:
lm(formula = mydata$H4.5 ~ mydata$smuse_hour_day)
Residuals:
Min 1Q Median 3Q Max
-61.699 -10.372 -0.505 9.812 39.628
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 60.1066 0.6650 90.383 <2e-16 ***
mydata$smuse_hour_day 0.5308 0.2796 1.899 0.0578 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 17.88 on 1258 degrees of freedom
(因為不存在,742 個觀察量被刪除了)
Multiple R-squared: 0.002857, Adjusted R-squared: 0.002065
F-statistic: 3.605 on 1 and 1258 DF, p-value: 0.05784计算方法如下(使用 R ):
1.排除变量的缺失值(只限定变量皆有值的样本)
- 计算x, y变量各自的平均数
- 计算分子:协方差(共变数)
- 计算分母:x的方差(变异数)
- \(beta\) 回归系数
线性回归系数(beta)的 SE
SE(Standard Error)标准误的公式为:
\[ SE(\hat{\beta}_1) = \sqrt{ \frac{MSE}{\sum_{i=1}^{n} (X_i - \bar{X})^2} } \]
其中:
残差均方和:
\[ MSE = \frac{SSE}{n-2} \]
残差平方和:
\[ SSE = \sum_{i=1}^{n} (Y_i - \hat{Y}_i)^2 \]
因此:
\[ SE(\hat{\beta}_1) =\sqrt{ \frac{SSE}{(n-2)\sum_{i=1}^{n} (X_i - \bar{X})^2} } \]
以 Figure 24 中的 \(Std.Error(beta)=0.267\) 为例,计算方法如下:
1.计算SSE(误差平方和)
如:Figure 21 中 ANOVA报表所示的 SSE(Sum of Square Error)
\[ SSE = 414442.716 \]
2.计算样本数减去2
样本数为1295, 因此:
\[ n - 2 = 1295 - 2 = 1293 \]
3.计算分母
\[ \sum_{i=1}^{n} (X_i - \bar{X})^2 = 1295.248 \]
4.计算SE(beta)
\[ \begin{align} SE(\hat{\beta}_1) &= \sqrt{ \frac{SSE}{(n-2)\sum_{i=1}^{n} (X_i - \bar{X})^2} } \\ &= \sqrt{ \frac{414442.716}{1293 \times 1295.248} } \\ &= \sqrt{0.07129} \\ &= 0.267 \end{align} \]
线性回归系数(beta)对应的 t
线性回归系数(\(beta\))对应的t检验统计量,计算公式如下:
\[ t = \frac{\hat{\beta} - \beta_0}{SE(\hat{\beta})} \]
其中:
\(\hat{\beta}\):估计的回归系数
\(\beta_0\):原假设下的系数值(通常为 0)
\(SE(\hat{\beta})\):回归系数的标准误
Figure 24 中 \(t = 2.246\),计算方法如下:
\(\hat{\beta} = 0.601\),
\(SE(\hat{\beta}) = 0.267\),
\(\beta_0 = 0\)
所以t值等于:
\[ \begin{align} t & = \frac{0.601 - 0}{0.267} \\ &= \frac{0.601}{0.267} \approx 2.25 \\ \end{align} \]
线性回归系数(beta)对应的 P
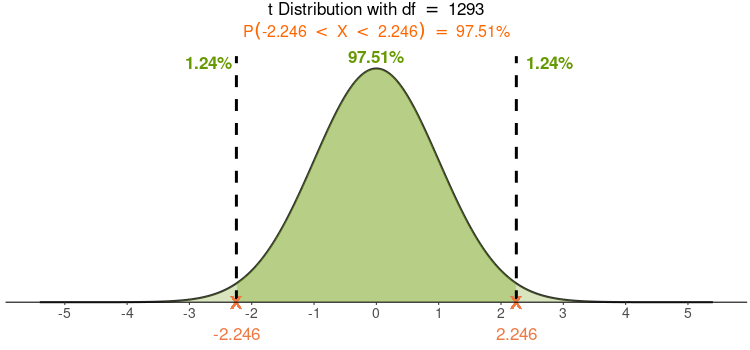
Figure 24 中,\(beta=0.601,t=2.246,df=n-2=1295-2=1293\), 查阅t分配表(或使用统计软件),可得 \(P\)= 2.5% = 0.025$ ,如 Figure 47 所示 (1.24% + 1.24% = 2.48% ≈ 2.5%)
线性回归系数(beta)的95% CI
Figure 24 中,\(beta=0.601\),\(SE(beta)=0.267\), 95% CI =\([0.076 ~ 1.126]\)之间,不包括0。
beta 的95% CI 计算公式如下:
\(beta \pm t_{(α/2, n-2)} \times SE(beta)\)
其中: \(t_{(α/2, n-2)}\):t分配临界值(双尾)
\(α=0.05\),\(α/2=0.025\),
n-2=1295-2=1293(自由度df=1293)。
查阅t分配表(或使用统计软件),可得 \(t_{(0.025, 1293)}=1.96\) 如 Figure 48 所示:
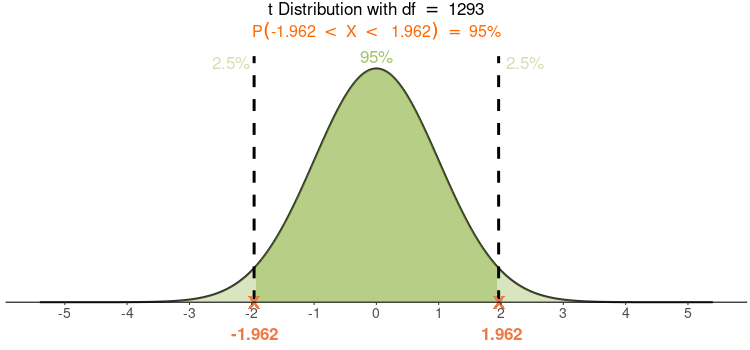
代入数值: \(beta=0.601, t=1.96, SE(beta)=0.267\) 得到 \(beta\) 的 95% CI: \([0.07, 1.12]\)
\[ \begin{align} &beta \pm t_{(α/2, n-2)} \times SE(beta) \\ &= 0.601 \pm 1.96 \times 0.267 \\ &= 0.601 \pm 0.52332 \\ &= [0.07768 ~ 1.12432] \approx [0.07 ~ 1.12] \\ \end{align} \]